라즈베리 파이 클러스터로 Distributed Llama 완전 가이드 - 엣지 AI의 새로운 가능성
이전 글에서는 ByteShape의 ShapeLearn을 활용하여 단일 라즈베리 파이 5 (16GB)에서 고급 양자화 기술을 통해 Qwen3-30B를 구동하는 방법을 살펴보았습니다. 이번 글에서는 완전히 다른 접근 방식인 분산 클러스터 방식을 소개해 드립니다.
4대의 라즈베리 파이 5를 네트워크로 연결하여 하나의 강력한 AI 추론 시스템을 구축하는 방법을 상세히 알아보겠습니다. 흥미롭게도 이 두 가지 접근 방식은 동일한 Qwen3-30B 모델을 실행하면서도 전혀 다른 철학과 기술 스택을 사용합니다. 단일 노드 방식은 하드웨어 효율성을 극대화하는 반면, 분산 클러스터 방식은 여러 장치의 연산 능력을 결합하여 더 높은 처리 속도를 달성합니다.

목 차
1. Distributed Llama 프로젝트 개요
프로젝트 소개와 핵심 철학
Distributed Llama는 Bartłomiej Tadych가 개발한 오픈소스 프로젝트로, 가정용 장치들을 연결하여 강력한 LLM 추론 클러스터를 구축할 수 있게 해주는 혁신적인 도구입니다. 이 프로젝트의 핵심 철학은 "더 많은 장치가 더 빠른 추론을 의미한다"는 것으로, 텐서 병렬화(Tensor Parallelism)와 이더넷을 통한 고속 동기화를 활용하여 분산 추론을 구현합니다.
현재 GitHub에서 2,800개 이상의 스타를 받으며 활발하게 개발되고 있으며, Linux, macOS, Windows를 모두 지원합니다. 특히 ARM 아키텍처와 x86_64 AVX2 CPU에 최적화되어 있어 라즈베리 파이와 같은 SBC(Single Board Computer)에서 효율적으로 동작합니다.
분산 추론의 기술적 배경
분산 추론(Distributed Inference)은 대규모 언어 모델을 여러 컴퓨팅 장치에 분산시켜 실행하는 기술입니다. 일반적으로 LLM 추론에는 두 가지 주요 병렬화 기법이 사용되는데, 텐서 병렬화(Tensor Parallelism)는 모델의 개별 레이어를 여러 GPU 또는 장치에 분할하여 동시에 계산하는 방식이며, 파이프라인 병렬화(Pipeline Parallelism)는 모델을 수직으로 분할하여 첫 번째 레이어 그룹은 첫 번째 장치에서, 다음 레이어 그룹은 다음 장치에서 순차적으로 처리하는 방식입니다. Distributed Llama는 주로 텐서 병렬화를 채택하여 모든 노드가 동시에 작업을 수행할 수 있도록 설계되었습니다.
텐서 병렬화의 핵심 장점은 모든 장치가 동시에 연산을 수행한다는 점입니다. 파이프라인 병렬화에서는 앞선 장치의 결과를 기다려야 하지만, 텐서 병렬화에서는 각 장치가 독립적인 텐서 슬라이스를 처리한 후 결과를 집계합니다. 이로 인해 메모리 대역폭이 효과적으로 배가되어 단일 장치에서 발생할 수 있는 병목 현상을 크게 줄일 수 있습니다. 다만 텐서 병렬화는 장치 간 통신 오버헤드가 발생하므로, 고속 네트워크 연결이 성능에 중요한 영향을 미칩니다.
분산 추론 전체 흐름도 | 초기화부터 추론, 성능 측정까지의 전체 파이프라인
flowchart TB
subgraph INIT["초기화 단계"]
direction LR
A1["ROOT: 모델 파일 로드<br/>qwen3_30b_a3b_q40.m<br/>(17GB)"] --> A2["토크나이저 로드<br/>vocab: 151,669"]
A2 --> A3["네트워크 소켓 연결<br/>WORKER 1,2,3"]
end
subgraph DIST["가중치 분배"]
direction TB
B1["텐서 슬라이싱<br/>48 레이어 분할"] --> B2["WORKER별 할당<br/>12 레이어/노드"]
B2 --> B3["네트워크 전송<br/>~20MB 전송"]
end
subgraph INFER["추론 단계 - 토큰별 반복"]
direction TB
C1["프롬프트 토큰화"] --> C2["Attention 연산<br/>병렬 분산"]
C2 --> C3["MoE 라우팅<br/>8/128 전문가 활성화"]
C3 --> C4["FFN 연산<br/>각 노드 독립 처리"]
C4 --> C5["AllReduce 동기화<br/>결과 집계"]
C5 --> C6["다음 토큰 샘플링"]
C6 -.->|반복| C2
end
subgraph PERF["성능 측정"]
direction LR
D1["평가: 14.33 tok/s"] --- D2["예측: 13.04 tok/s"]
D2 --- D3["동기화: 14~94ms"]
end
INIT --> DIST
DIST --> INFER
INFER --> PERF
style INIT fill:#fff3e0,stroke:#ff9800
style DIST fill:#e3f2fd,stroke:#2196f3
style INFER fill:#f3e5f5,stroke:#9c27b0
style PERF fill:#e8f5e9,stroke:#4caf50
Qwen3-30B MoE 모델의 특성
이번 벤치마크에서 사용된 Qwen3-30B는 알리바바의 Qwen 팀이 개발한 Mixture of Experts(MoE) 아키텍처 기반의 대규모 언어 모델입니다. MoE 모델은 모든 파라미터를 동시에 활성화하지 않고, 각 입력에 대해 일부 "전문가(Expert)" 네트워크만 선택적으로 활성화하여 연산 효율성을 높입니다. Qwen3-30B는 총 48개의 레이어와 128개의 전문가를 갖추고 있으며, 각 추론 단계에서 8개의 전문가만 활성화됩니다. 이러한 구조 덕분에 30B(300억) 파라미터 규모이면서도 실제 활성 파라미터는 3B 수준으로 유지되어 "A3B"라는 명칭이 붙었습니다.
MoE 아키텍처의 장점은 메모리 요구량 대비 높은 성능을 제공한다는 것입니다. 전통적인 Dense 모델에서는 모든 파라미터가 매 추론마다 사용되지만, MoE에서는 라우터(Router)가 입력 토큰을 분석하여 가장 적합한 전문가들에게만 연산을 위임합니다. 이로 인해 메모리에는 전체 30B 파라미터를 로드해야 하지만, 실제 연산량은 3B 모델 수준으로 유지됩니다. 분산 환경에서 MoE 모델을 실행할 때는 전문가 병렬화(Expert Parallelism)라는 추가적인 최적화 기법을 적용할 수도 있습니다.
Qwen3-30B MoE 아키텍처 | Mixture of Experts 모델 구조 설명
flowchart TB
subgraph INPUT["입력 처리"]
I1["토큰 임베딩<br/>vocab: 151,936"]
end
subgraph LAYERS["48개 Transformer 레이어"]
direction TB
L1["Layer 1-12<br/>노드 1 처리"]
L2["Layer 13-24<br/>노드 2 처리"]
L3["Layer 25-36<br/>노드 3 처리"]
L4["Layer 37-48<br/>노드 4 처리"]
subgraph MOE["MoE 구조 - 각 레이어"]
M1["라우터<br/>토큰 to 전문가 매핑"]
M2["128개 전문가 중<br/>8개 활성화"]
M3["가중 합산"]
M1 --> M2 --> M3
end
end
subgraph OUTPUT["출력 생성"]
O1["LayerNorm"]
O2["LM Head"]
O3["다음 토큰<br/>확률 분포"]
end
INPUT --> LAYERS
L1 --> L2 --> L3 --> L4
LAYERS --> OUTPUT
O1 --> O2 --> O3
style INPUT fill:#e8f5e9,stroke:#4caf50
style LAYERS fill:#fff3e0,stroke:#ff9800
style MOE fill:#fce4ec,stroke:#e91e63
style OUTPUT fill:#e3f2fd,stroke:#2196f32. 시스템 아키텍처 상세 분석
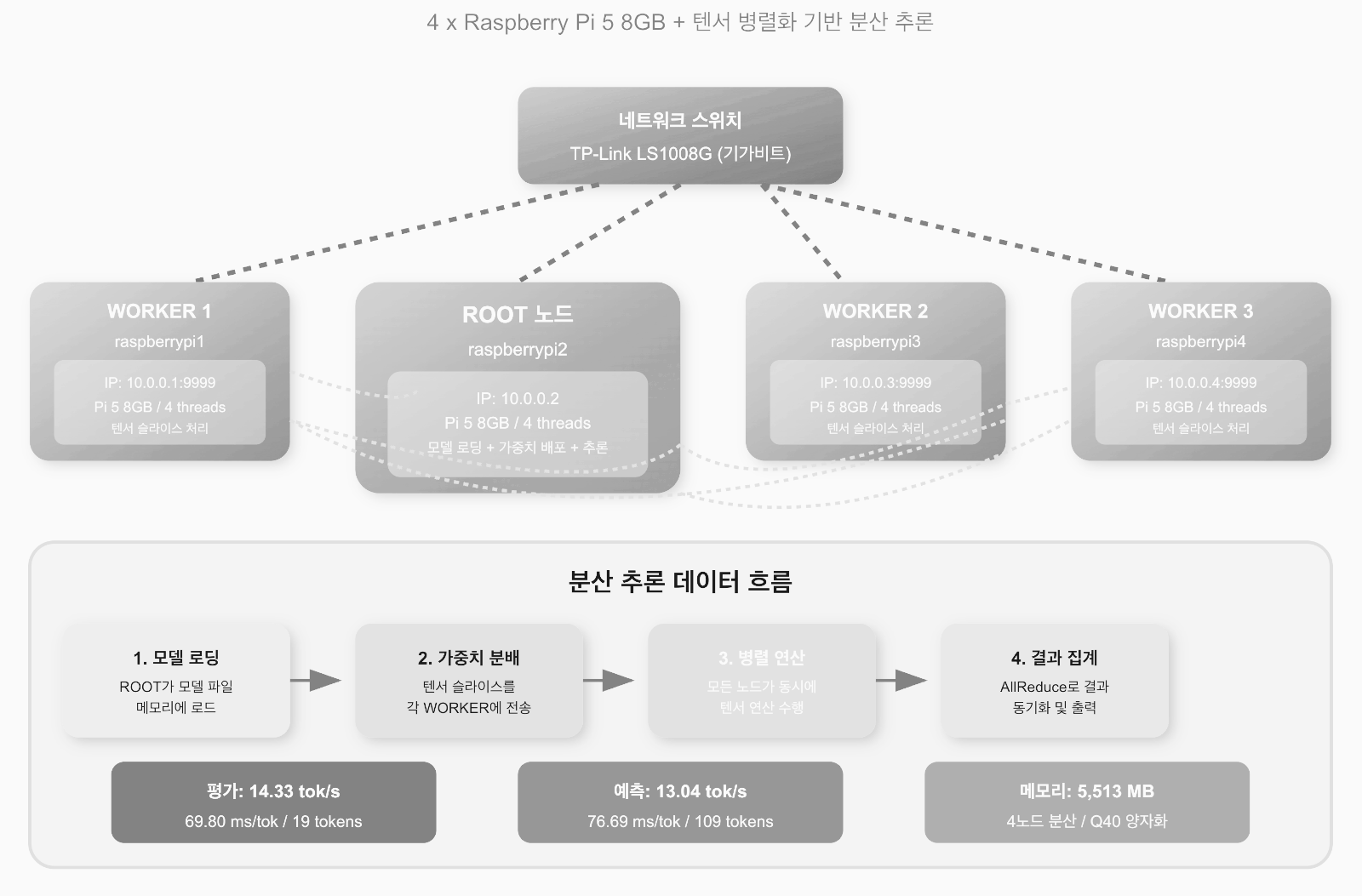
클러스터 구성 개요
이번 벤치마크에서 사용된 클러스터는 4대의 라즈베리 파이 5 8GB로 구성되어 있습니다.
Distributed Llama의 아키텍처는 ROOT 노드와 WORKER 노드로 구분되며, ROOT 노드는 모델 로딩, 가중치 배포, 추론 동기화를 담당하고 WORKER 노드들은 분배받은 텐서 슬라이스를 처리합니다. 모든 노드는 TP-Link LS1008G 기가비트 스위치를 통해 연결되어 있으며, 각 장치에는 고정 IP 주소가 할당되어 있습니다. 이러한 구성은 네트워크 지연을 최소화하고 안정적인 통신을 보장합니다.
클러스터의 물리적 구성을 살펴보면, ROOT 노드(raspberrypi2)는 IP 주소 10.0.0.2를 사용하고, 세 대의 WORKER 노드는 각각 10.0.0.1, 10.0.0.3, 10.0.0.4의 IP 주소를 사용합니다. 모든 WORKER 노드는 포트 9999에서 ROOT 노드의 연결을 대기합니다. 이 구성에서 흥미로운 점은 Distributed Llama가 2^n 개의 노드만 지원한다는 것으로, 1, 2, 4, 8, 16대 등으로만 클러스터를 구성할 수 있습니다. 또한 최대 노드 수는 모델의 KV 헤드 수에 의해 제한됩니다.
네트워크 토폴로지와 메시 아키텍처
Distributed Llama v0.11.0 버전부터 클러스터 내 모든 노드는 메시 토폴로지(Mesh Topology)로 상호 연결됩니다. 이전 버전에서는 스타 토폴로지를 사용하여 ROOT 노드가 모든 통신의 중심이 되었지만, 메시 토폴로지에서는 모든 노드가 서로 직접 통신할 수 있습니다. 이러한 변경으로 인해 마지막 레이어에서 발생하던 병목 현상이 크게 개선되었습니다. 벤치마크 결과에 따르면, 이 아키텍처 변경으로 Llama 3.2 1B 모델에서 2.1배의 속도 향상이 달성되었습니다.
메시 토폴로지의 핵심 이점은 분산 오버헤드의 균등화입니다. 모든 레이어가 모든 노드에 분산되며, 노멀라이제이션(Normalization) 레이어는 각 노드에서 중복 계산됩니다. 이 중복 계산은 상대적으로 빠른 연산이므로 전체 성능에 큰 영향을 미치지 않으면서, 네트워크 동기화 지점을 최소화하는 효과를 가져옵니다. 벤치마크 로그에서 확인할 수 있듯이, 각 토큰 생성 시 송신(Sent) 636KB, 수신(Recv) 1,057KB의 데이터가 교환되며, 동기화(Sync) 시간은 14~94ms 범위에서 변동합니다.
클러스터 네트워크 토폴로지 | 4대의 라즈베리 파이가 어떻게 연결되는지 시각화
graph TB
SWITCH["네트워크 스위치<br/>TP-Link LS1008G"]
ROOT["ROOT 노드<br/>Pi5 8GB | 10.0.0.2<br/>모델 로딩 + 조정 + 추론"]
W1["WORKER 1<br/>Pi5 8GB | 10.0.0.1:9999<br/>텐서 슬라이스 처리"]
W2["WORKER 2<br/>Pi5 8GB | 10.0.0.3:9999<br/>텐서 슬라이스 처리"]
W3["WORKER 3<br/>Pi5 8GB | 10.0.0.4:9999<br/>텐서 슬라이스 처리"]
SWITCH <-->|1Gbps| ROOT
SWITCH <-->|1Gbps| W1
SWITCH <-->|1Gbps| W2
SWITCH <-->|1Gbps| W3
ROOT <-.->|메시 연결| W1
ROOT <-.->|메시 연결| W2
ROOT <-.->|메시 연결| W3
W1 <-.->|메시 연결| W2
W1 <-.->|메시 연결| W3
W2 <-.->|메시 연결| W3
style ROOT fill:#ff6b6b,stroke:#ee5a24,color:#fff
style W1 fill:#74b9ff,stroke:#0984e3,color:#fff
style W2 fill:#74b9ff,stroke:#0984e3,color:#fff
style W3 fill:#74b9ff,stroke:#0984e3,color:#fff
style SWITCH fill:#55efc4,stroke:#00b894메모리 분배 전략
Distributed Llama에서 신경망의 메모리 사용량은 모든 노드에 분산됩니다.
이번 벤치마크에서 Qwen3-30B Q40 모델의 총 메모리 요구량은 약 5,513MB이며, 이는 4대의 노드에 분배됩니다. ROOT 노드는 추론 조정과 가중치 배포 역할을 추가로 담당하므로 WORKER 노드보다 약간 더 많은 메모리를 사용합니다. 각 라즈베리 파이 5 8GB는 충분한 메모리 여유를 가지고 모델 슬라이스를 처리할 수 있으며, 최대 시퀀스 길이는 4,096 토큰으로 설정되었습니다.
메모리 효율성 측면에서 Q40 양자화는 모델 가중치를 4비트로 압축하여 메모리 사용량을 크게 줄입니다. 원본 FP16 모델이 약 60GB를 요구하는 것에 비해, Q40 양자화 버전은 약 17GB로 압축됩니다. 추론 과정에서 사용되는 버퍼는 Q80(8비트) 정밀도로 설정되어 계산 정확도와 성능 사이의 균형을 유지합니다. 이러한 양자화 조합은 라즈베리 파이의 제한된 메모리 환경에서 대규모 모델을 실행할 수 있게 해주는 핵심 요소입니다.
3. 하드웨어 구성 및 설정 가이드
필요 하드웨어 목록
분산 LLM 클러스터를 구축하기 위해서는 다음과 같은 하드웨어가 필요합니다.
- 라즈베리 파이 5 8GB 4대가 핵심 연산 장치로 사용되며,
- 기가비트 이더넷 스위치(예: TP-Link LS1008G)로 장치들을 연결합니다.
- 각 라즈베리 파이에는 안정적인 전원 공급을 위한 27W USB-C 전원 어댑터가 필요하며,
- OS와 모델 저장을 위한 고속 microSD 카드(64GB 이상 권장) 또는 NVMe SSD가 필요합니다.
- 네트워크 연결을 위한 Cat6 이더넷 케이블 4개와 방열 및 냉각 솔루션도 준비해야 합니다.
하드웨어 선택 시 주의할 점이 있습니다. 전원 공급 문제는 라즈베리 파이 클러스터에서 흔히 발생하는 성능 저하 원인입니다. 불충분한 전원은 CPU 쓰로틀링을 유발하여 추론 속도를 크게 떨어뜨릴 수 있습니다. 공식 27W 전원 어댑터를 사용하거나, 충분한 출력을 가진 멀티포트 USB-C 충전 허브를 사용하는 것이 좋습니다. 또한 라즈베리 파이 5는 발열이 상당하므로 액티브 쿨러나 히트싱크가 장착된 케이스를 사용하는 것이 권장됩니다.
운영체제 및 네트워크 설정
각 라즈베리 파이에는 최신 Raspberry Pi OS (64-bit)를 설치합니다. 설치 후 네트워크 설정을 위해 각 노드에 고정 IP 주소를 할당해야 합니다. 네트워크 구성 파일을 편집하여 고정 IP를 설정하고, 모든 노드 간의 통신이 원활한지 ping 명령으로 확인합니다. SSH를 활성화하면 ROOT 노드에서 모든 WORKER 노드를 원격으로 관리할 수 있어 편리합니다. 호스트명을 각 노드의 역할에 맞게 설정하면 관리가 더욱 수월해집니다.
Bullseye버전에서의 수동 설정
다음은 Raspberry Pi OS에서 고정 IP 주소를 설정하는 방법입니다. /etc/dhcpcd.conf 파일을 편집하여 각 노드에 맞는 IP 주소를 설정합니다.
# ROOT 노드 (raspberrypi2) 설정 예시
sudo nano /etc/dhcpcd.conf
# 파일 끝에 다음 내용 추가
interface eth0
static ip_address=10.0.0.2/24
static routers=10.0.0.1
# 변경사항 적용
sudo systemctl restart dhcpcdBookWorm에서 NetworkManager를 이용한 설정
라즈베리 파이 5(Raspberry Pi OS Bookworm 이상)는 dhcpcd 대신 NetworkManager를 사용하므로, 클러스터 구축 시 아래의 설정 방식을 권장합니다.
추천 방식 | nmtui (GUI 기반 터미널 도구)
클러스터의 각 노드에 접속하여 가장 직관적으로 설정할 수 있는 방법입니다.
터미널에서 sudo nmtui 실행
Edit a connection 선택 → 사용 중인 연결(예: Wired connection 1) 선택
IPv4 CONFIGURATION을 <Automatic>에서 <Manual>로 변경
Addresses, Gateway, DNS servers를 입력 후 OK를 눌러 저장
sudo systemctl restart NetworkManager로 적용
nmcli 방식 | 스크립트/자동화용
여러 대의 노드를 한꺼번에 세팅할 때 유용합니다.
# 이더넷 연결 이름 확인 (보통 "Wired connection 1")
nmcli connection show
# 고정 IP 설정 (예: 192.168.0.10번 노드)
sudo nmcli connection modify "Wired connection 1" \
ipv4.addresses 192.168.0.10/24 \
ipv4.gateway 192.168.0.1 \
ipv4.dns "8.8.8.8,1.1.1.1" \
ipv4.method manual
# 설정 적용
sudo nmcli connection up "Wired connection 1"
클러스터 운영을 위한 네트워크
- Hostname설정: 각 노드를 쉽게 구분할 수 있도록 sudo hostnamectl set-hostname node01 명령어로 이름을 지정하세요. 라즈베리파이 공식 튜토리얼에서도 권장하는 방식입니다.
- 유선 연결 권장: 클러스터 노드 간 데이터 동기화(etcd 등)를 위해 Wi-Fi보다는 기가비트 스위치를 통한 유선 연결이 훨씬 안정적입니다.
- SSH 키 복사: 노드 간 비밀번호 없이 접속할 수 있도록 ssh-keygen 후 ssh-copy-id를 통해 마스터 노드의 키를 각 워커 노드에 복사해두면 운영이 편리합니다.
WORKER 노드들도 동일한 방식으로 각각 10.0.0.1, 10.0.0.3, 10.0.0.4의 IP 주소를 설정합니다. 모든 설정이 완료되면 각 노드에서 다른 노드들로 ping 테스트를 수행하여 네트워크 연결 상태를 확인해야 합니다. 지연 시간이 1ms 이하로 나타나야 최적의 성능을 기대할 수 있습니다.
Distributed Llama 설치
Distributed Llama는 C++로 작성되어 있으며, 컴파일을 위해 빌드 도구가 필요합니다. 모든 노드에 동일한 버전의 Distributed Llama를 설치해야 합니다. 최신 버전(v0.16.0 이상)은 Qwen3 MoE 모델과 Vulkan GPU 가속을 지원합니다. 설치 과정은 소스 코드 다운로드, 컴파일, 실행 파일 생성의 순서로 진행됩니다. Python 3가 설치되어 있다면 launch.py 스크립트를 사용하여 모델 다운로드와 실행을 자동화할 수 있습니다.
# 모든 노드에서 실행
sudo apt update && sudo apt upgrade -y
sudo apt install -y build-essential git python3 python3-pip
# 소스 코드 다운로드
git clone https://github.com/b4rtaz/distributed-llama.git
cd distributed-llama
# 컴파일
make
# 설치 확인
./dllama --help
컴파일이 완료되면 dllama 실행 파일이 생성됩니다. 이 파일은 inference, chat, worker 세 가지 모드를 지원합니다. WORKER 노드들에서는 dllama worker 명령을 실행하여 대기 상태로 만들고, ROOT 노드에서 추론 명령을 실행하면 자동으로 클러스터가 구성됩니다.
4. 모델 준비 및 변환
모델 다운로드 옵션
Qwen3-30B 모델을 Distributed Llama에서 사용하기 위해서는 전용 형식으로 변환된 모델 파일이 필요합니다.
가장 간단한 방법은 launch.py 스크립트를 사용하는 것으로, 이 스크립트는 모델과 토크나이저를 자동으로 다운로드하고 적절한 디렉토리에 배치합니다. 수동 설치를 원하는 경우에는 Hugging Face에서 원본 모델을 다운로드한 후 Distributed Llama의 변환 도구를 사용하여 변환할 수 있습니다. 변환된 모델은 .m 확장자를, 토크나이저는 .t 확장자를 사용합니다.
# 자동 다운로드 및 실행 (권장)
python launch.py qwen3_30b_a3b_q40
# 또는 수동으로 모델 다운로드 후 변환
# 1. Hugging Face에서 모델 다운로드
# 2. 변환 스크립트 실행
python converter/convert.py --model-path /path/to/qwen3-30b --output-path models/양자화 형식 이해
Distributed Llama는 현재 두 가지 양자화 조합을 지원합니다.
- 첫 번째는 Q40 모델 + Q80 버퍼로, 모델 가중치를 4비트로 양자화하고 중간 연산 버퍼는 8비트를 사용합니다.
- 두 번째는 F32 모델 + F32 버퍼로, 양자화 없이 전체 32비트 부동소수점을 사용합니다.
메모리 제약이 있는 라즈베리 파이 환경에서는 Q40 양자화가 사실상 유일한 선택지입니다. Q40 양자화는 모델 크기를 약 75% 줄이면서도 허용 가능한 수준의 품질 저하만 발생시킵니다.
이번 벤치마크에서 사용된 Qwen3-30B A3B Q40 모델의 구체적인 스펙을 살펴보면, 아키텍처는 Qwen3 MoE이고, 활성화 함수는 SiLU입니다. 차원(Dim)은 2,048이고, 쿼리 차원(QDim)은 4,096, KV 차원은 512입니다. 히든 차원은 6,144이며, 어휘 크기는 151,936 토큰입니다. MoE 구성으로는 128개의 전문가 중 8개가 활성화되며, MoE 히든 차원은 768입니다. RoPE 임베딩은 Falcon 타입을 사용하고 theta 값은 10,000,000입니다.
모델 파일 배포
클러스터에서 분산 추론을 실행하려면 모델 파일을 모든 노드에서 접근할 수 있어야 합니다.
가장 간단한 방법은 각 노드에 모델 파일을 복사하는 것이지만, NFS나 Samba와 같은 네트워크 파일 시스템을 구성하면 저장 공간을 절약하고 모델 업데이트를 쉽게 할 수 있습니다. Distributed Llama는 모델 로딩 시 ROOT 노드가 가중치를 WORKER 노드로 배포하므로, 실제로는 ROOT 노드에만 전체 모델 파일이 있으면 됩니다. 다만 토크나이저 파일은 ROOT 노드에서만 사용됩니다.
# ROOT 노드에서 모델 디렉토리 확인
ls -la models/qwen3_30b_a3b_q40/
# dllama_model_qwen3_30b_a3b_q40.m # 모델 파일 (약 17GB)
# dllama_tokenizer_qwen3_30b_a3b_q40.t # 토크나이저 파일
# WORKER 노드는 실행 파일만 있으면 됨
# 모델 가중치는 ROOT에서 네트워크를 통해 배포됨5. 클러스터 실행 및 벤치마크
WORKER 노드 시작
분산 추론을 실행하기 전에 모든 WORKER 노드에서 dllama worker 프로세스를 먼저 시작해야 합니다.
각 WORKER 노드는 지정된 포트에서 ROOT 노드의 연결을 대기합니다. 스레드 수는 CPU 코어 수를 초과하지 않도록 설정해야 하며, 라즈베리 파이 5의 경우 4개의 코어를 가지고 있으므로 --nthreads 4로 설정합니다. WORKER 프로세스는 systemd 서비스로 등록하여 자동 시작되도록 구성할 수 있습니다.
# WORKER 1 (10.0.0.1)에서 실행
./dllama worker --port 9999 --nthreads 4
# WORKER 2 (10.0.0.3)에서 실행
./dllama worker --port 9999 --nthreads 4
# WORKER 3 (10.0.0.4)에서 실행
./dllama worker --port 9999 --nthreads 4
각 WORKER가 정상적으로 시작되면 "Listening on port 9999" 메시지가 출력됩니다. 모든 WORKER가 대기 상태가 되면 ROOT 노드에서 추론을 시작할 준비가 완료됩니다. WORKER 프로세스는 ROOT 노드의 연결을 기다리며, 연결이 수립되면 자동으로 모델 슬라이스를 수신하고 추론에 참여합니다.
ROOT 노드에서 추론 실행
ROOT 노드에서 dllama inference 명령을 실행하면 클러스터가 구성되고 추론이 시작됩니다. 핵심 파라미터로는 모델 경로, 토크나이저 경로, 버퍼 부동소수점 타입, 스레드 수, 최대 시퀀스 길이, 그리고 WORKER 노드 주소 목록이 필요합니다. 명령어가 실행되면 먼저 모든 WORKER에 연결하고, 모델을 로드한 후, 가중치를 분배하고, 마지막으로 추론을 수행합니다. 전체 과정에서 상세한 로그가 출력되어 진행 상황을 모니터링할 수 있습니다.
# ROOT 노드 (10.0.0.2)에서 실행
./dllama inference \
--prompt "<|im_start|>user Please explain me where is Poland as I have 1 year<|im_end|> <|im_start|>assistant " \
--steps 128 \
--model models/qwen3_30b_a3b_q40/dllama_model_qwen3_30b_a3b_q40.m \
--tokenizer models/qwen3_30b_a3b_q40/dllama_tokenizer_qwen3_30b_a3b_q40.t \
--buffer-float-type q80 \
--nthreads 4 \
--max-seq-len 4096 \
--workers 10.0.0.1:9999 10.0.0.3:9999 10.0.0.4:9999벤치마크 결과 분석
실제 벤치마크 결과를 분석해 보겠습니다.
- 평가(Evaluation) 단계에서는 32개의 배치와 19개의 토큰을 처리하여 14.33 tok/s(토큰당 69.80ms)의 속도를 기록했습니다.
- 예측(Prediction) 단계에서는 109개의 토큰을 생성하여 13.04 tok/s(토큰당 76.69ms)의 속도를 달성했습니다.
- 평가 단계에서 송신 12,084KB, 수신 20,085KB의 데이터가 교환되었으며,
- 예측 단계에서는 각 토큰당 송신 636KB, 수신 1,057KB가 교환되었습니다. 동기화 시간은 토큰당 14~94ms 범위로 변동했습니다.
이 결과를 이전 글에서 다룬 단일 노드 방식과 비교하면 흥미로운 차이점이 드러납니다. ShapeLearn을 사용한 단일 Pi 5 16GB 구성에서는 8.03 tok/s를 달성한 반면, 4대의 Pi 5 8GB 클러스터에서는 13.04 tok/s를 달성했습니다. 분산 클러스터 방식이 약 62% 더 빠른 추론 속도를 보여주지만, 하드웨어 총 메모리는 32GB(4 × 8GB)로 단일 노드의 16GB보다 두 배 많습니다. 따라서 메모리 효율성 측면에서는 단일 노드 방식이 우위에 있고, 순수 성능 측면에서는 분산 클러스터 방식이 우위에 있습니다.
성능 벤치마크 타임라인 | 실제 토큰 생성 과정의 시간 분석
gantt
title Qwen3-30B 토큰 생성 타임라인 - 분산 클러스터
dateFormat X
axisFormat %L ms
section 평가 단계
배치 처리 - 32 batches :a1, 0, 996
동기화 :a2, 996, 330
section 예측 단계
토큰 1 - Of :b1, 1326, 49
동기화 :s1, 1375, 37
토큰 2 - course :b2, 1412, 50
동기화 :s2, 1462, 94
토큰 3 - ! :b3, 1556, 60
동기화 :s3, 1616, 37
토큰 4 - Let :b4, 1653, 60
동기화 :s4, 1713, 18
이후 토큰들... :b5, 1731, 60006. 두 가지 접근 방식 비교 분석

기술적 차이점
단일 노드 방식과 분산 클러스터 방식은 동일한 Qwen3-30B 모델을 실행하지만 근본적으로 다른 기술 철학을 가지고 있습니다. 단일 노드 방식(ByteShape ShapeLearn)은 고급 양자화 기술(Q3_K_S-2.70bpw)을 사용하여 모델 크기를 극한까지 압축하고, 단일 장치의 메모리 한계 내에서 모든 연산을 수행합니다. 반면 분산 클러스터 방식(Distributed Llama)은 표준 Q40 양자화를 사용하면서 여러 장치의 연산 능력을 결합하여 처리량을 높입니다. 양자화 강도 측면에서 ShapeLearn의 2.70bpw는 Q40의 약 4bpw보다 더 공격적이므로, 이론적으로는 분산 클러스터 방식이 더 높은 응답 품질을 제공할 수 있습니다.
네트워크 의존성도 중요한 차이점입니다. 단일 노드 방식은 네트워크 연결이 전혀 필요 없어 완전히 오프라인으로 동작할 수 있습니다. 분산 클러스터 방식은 고속 로컬 네트워크가 필수이며, 네트워크 품질이 추론 성능에 직접적인 영향을 미칩니다. 벤치마크에서 확인된 바와 같이 토큰당 636KB~1,057KB의 데이터가 교환되므로, 기가비트 이더넷 이상의 네트워크 대역폭이 권장됩니다. WiFi 연결은 지연과 불안정성으로 인해 성능이 크게 저하될 수 있습니다.
성능 및 비용 비교
두 접근 방식의 정량적 비교를 정리하면 다음과 같습니다.
- 단일 노드 방식은 라즈베리 파이 5 16GB 1대(약 $80)로 8.03 tok/s를 달성하며, 추가로 필요한 장비가 없습니다.
- 분산 클러스터 방식은 라즈베리 파이 5 8GB 4대(약 $240)와 네트워크 스위치(약 $20)로 13.04 tok/s를 달성합니다.
순수 하드웨어 비용 대비 성능을 계산하면, 단일 노드는 달러당 0.10 tok/s, 분산 클러스터는 달러당 0.05 tok/s로 단일 노드 방식의 비용 효율이 약 2배 높습니다. 그러나 절대 성능이 중요한 경우에는 분산 클러스터 방식이 62% 더 빠른 응답을 제공합니다.
전력 소비 측면에서도 차이가 있습니다. 라즈베리 파이 5는 부하 시 약 8~10W를 소비하므로, 단일 노드 방식은 최대 10W, 분산 클러스터 방식은 최대 40W의 전력을 소비합니다. 장기간 운영을 고려할 때 전력 비용도 무시할 수 없는 요소입니다. 다만 두 방식 모두 일반적인 GPU 서버(수백 와트)에 비하면 매우 낮은 전력 소비를 보여, 엣지 AI 환경에서의 실용성을 입증합니다.
사용 사례별 권장 사항
각 방식이 적합한 사용 사례를 정리해 보겠습니다. 단일 노드 방식(ShapeLearn)은 예산이 제한된 개인 프로젝트, 완전 오프라인 환경이 필요한 경우, 물리적 공간이 제한된 환경, 전력 소비를 최소화해야 하는 경우에 적합합니다. 반면 분산 클러스터 방식(Distributed Llama)은 최대 추론 속도가 중요한 경우, 기존에 여러 대의 라즈베리 파이를 보유한 경우, 향후 확장성을 고려하는 경우, 분산 시스템 학습 및 연구 목적에 적합합니다.
두 방식을 결합하는 하이브리드 접근도 고려할 수 있습니다. 예를 들어, 일상적인 간단한 쿼리는 단일 노드에서 처리하고, 복잡하거나 긴 응답이 필요한 작업은 분산 클러스터로 라우팅하는 방식입니다. 이를 위해서는 프록시 레이어를 구현하여 요청의 복잡도에 따라 적절한 백엔드를 선택하도록 해야 합니다. Distributed Llama의 API 서버 모드(dllama-api)를 활용하면 이러한 통합이 용이합니다.
두 가지 접근 방식 비교 | 단일 노드 vs 분산 클러스터의 핵심 차이점
graph LR
subgraph SINGLE["단일 노드 방식"]
direction TB
S1["Pi 5 16GB x 1"]
S2["ShapeLearn 양자화<br/>Q3_K_S-2.70bpw"]
S3["8.03 tok/s"]
S4["$80 | 10W"]
S1 --> S2 --> S3 --> S4
end
subgraph CLUSTER["분산 클러스터 방식"]
direction TB
C1["Pi 5 8GB x 4"]
C2["표준 양자화<br/>Q40 - 4bit"]
C3["13.04 tok/s"]
C4["$260 | 40W"]
C1 --> C2 --> C3 --> C4
end
SINGLE ---|"+62% 속도"| CLUSTER
style SINGLE fill:#fff5f5,stroke:#e17055
style CLUSTER fill:#f0f7ff,stroke:#0984e37. 고급 설정 및 최적화
네트워크 최적화
분산 클러스터의 성능을 극대화하기 위해서는 네트워크 최적화가 필수적입니다. 먼저 점보 프레임(Jumbo Frames)을 활성화하여 패킷당 전송할 수 있는 데이터 양을 늘립니다. 기본 MTU인 1500 바이트를 9000 바이트로 증가시키면 오버헤드가 줄어들어 대용량 데이터 전송 효율이 향상됩니다. 또한 TCP 버퍼 크기를 조정하여 네트워크 대역폭을 최대한 활용할 수 있습니다. 네트워크 스위치가 이러한 설정을 지원하는지 확인해야 하며, 모든 노드에 동일한 설정을 적용해야 합니다.
# 점보 프레임 활성화 (모든 노드에서 실행)
sudo ip link set eth0 mtu 9000
# 영구 설정을 위해 /etc/dhcpcd.conf에 추가
interface eth0
static ip_address=10.0.0.2/24
mtu 9000
# TCP 버퍼 크기 조정
sudo sysctl -w net.core.rmem_max=16777216
sudo sysctl -w net.core.wmem_max=16777216
sudo sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216"
sudo sysctl -w net.ipv4.tcp_wmem="4096 87380 16777216"
데이터 전송량 분석 | 토큰당 네트워크 트래픽 비율
pie showData
title 토큰당 네트워크 트래픽 - KB
"송신 Sent" : 636
"수신 Recv" : 1057CPU 최적화
라즈베리 파이 5의 CPU 성능을 최대로 활용하기 위한 설정도 중요합니다. CPU 주파수를 최대로 고정하면 추론 중 주파수 변동으로 인한 성능 저하를 방지할 수 있습니다. 라즈베리 파이 5의 기본 클럭은 2.4GHz이지만, 적절한 냉각 솔루션이 있다면 오버클럭을 통해 더 높은 성능을 얻을 수 있습니다. 다만 오버클럭은 시스템 안정성에 영향을 줄 수 있으므로 충분한 테스트 후 적용해야 합니다. Distributed Llama는 ARM의 NEON SIMD 명령어를 활용하여 최적화되어 있습니다.
# CPU 거버너를 performance로 설정
echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
# 부팅 시 자동 적용을 위해 /etc/rc.local에 추가
echo 'echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor' | sudo tee -a /etc/rc.local
# 오버클럭 설정 (선택사항, /boot/config.txt)
# over_voltage=2
# arm_freq=2800서비스 자동화
프로덕션 환경에서는 WORKER 프로세스를 systemd 서비스로 등록하여 자동 시작 및 복구를 구성하는 것이 좋습니다.
최신 버전의 Distributed Llama API 서버는 WORKER 크래시 시 자동으로 재연결을 시도하는 기능을 제공하여 클러스터의 안정성을 높입니다. 또한 모니터링 도구를 설정하여 각 노드의 상태, 메모리 사용량, 네트워크 트래픽을 추적할 수 있습니다. Prometheus와 Grafana 조합은 소규모 클러스터 모니터링에 적합합니다.
# /etc/systemd/system/dllama-worker.service 파일 생성
[Unit]
Description=Distributed Llama Worker
After=network.target
[Service]
Type=simple
User=pi
WorkingDirectory=/home/pi/distributed-llama
ExecStart=/home/pi/distributed-llama/dllama worker --port 9999 --nthreads 4
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
# 서비스 등록 및 시작
sudo systemctl daemon-reload
sudo systemctl enable dllama-worker
sudo systemctl start dllama-worker8. API 서버 구성 및 활용
REST API 서버 설정
Distributed Llama는 OpenAI 호환 REST API 서버를 제공하여 다양한 애플리케이션과 통합할 수 있습니다. dllama-api 명령으로 API 서버를 시작하면 외부 애플리케이션에서 HTTP 요청을 통해 추론을 수행할 수 있습니다. API 서버는 지속적인 서비스로 설계되어 장시간 운영에 적합하며, WORKER 노드 장애 시 자동 재연결을 시도합니다. 기본 포트는 8080이며, 다른 포트로 변경할 수 있습니다.
# API 서버 시작 (ROOT 노드에서)
./dllama-api \
--model models/qwen3_30b_a3b_q40/dllama_model_qwen3_30b_a3b_q40.m \
--tokenizer models/qwen3_30b_a3b_q40/dllama_tokenizer_qwen3_30b_a3b_q40.t \
--buffer-float-type q80 \
--nthreads 4 \
--max-seq-len 4096 \
--workers 10.0.0.1:9999 10.0.0.3:9999 10.0.0.4:9999 \
--port 8080API 호출 예시
API 서버가 실행되면 curl이나 Python requests 라이브러리를 사용하여 추론 요청을 보낼 수 있습니다. OpenAI 호환 엔드포인트를 제공하므로 기존 OpenAI API를 사용하던 애플리케이션을 쉽게 마이그레이션할 수 있습니다. 응답 형식도 OpenAI와 동일하여 별도의 파싱 로직 수정이 필요 없습니다.
import requests
import json
# 추론 요청 예시
url = "http://10.0.0.2:8080/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "qwen3-30b",
"messages": [
{"role": "user", "content": "대한민국의 수도는 어디인가요?"}
],
"max_tokens": 100,
"temperature": 0.7
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
print(result["choices"][0]["message"]["content"])웹 인터페이스 통합
API 서버를 기반으로 간단한 웹 인터페이스를 구축할 수 있습니다. Open WebUI나 Text Generation WebUI와 같은 오픈소스 프론트엔드는 OpenAI 호환 API를 지원하므로, API 엔드포인트만 설정하면 바로 사용할 수 있습니다. 이를 통해 라즈베리 파이 클러스터를 브라우저에서 접근 가능한 개인 AI 어시스턴트로 활용할 수 있습니다. 보안을 위해 내부 네트워크에서만 접근하도록 방화벽을 설정하거나, 리버스 프록시와 인증을 추가하는 것이 좋습니다.
9. 문제 해결 및 디버깅
일반적인 오류와 해결책
분산 클러스터 운영 중 발생할 수 있는 일반적인 오류와 해결 방법을 정리합니다.
- 연결 거부 오류는 WORKER 노드의 서비스가 실행 중이 아니거나 방화벽이 포트를 차단하는 경우 발생하며, WORKER 프로세스 상태와 방화벽 설정을 확인해야 합니다.
- 메모리 부족 오류는 --max-seq-len 값이 너무 크거나 다른 프로세스가 메모리를 점유하는 경우 발생하며, 시퀀스 길이를 줄이거나 불필요한 프로세스를 종료해야 합니다.
- 성능 저하는 전원 공급 부족으로 인한 CPU 쓰로틀링이나 네트워크 지연 때문에 발생할 수 있으며, 전원 어댑터 교체와 네트워크 상태 점검이 필요합니다.
# WORKER 연결 상태 확인
nc -zv 10.0.0.1 9999
# 방화벽 포트 개방 (필요한 경우)
sudo ufw allow 9999/tcp
# CPU 쓰로틀링 확인
vcgencmd get_throttled
# 결과가 0x0이 아니면 전원 또는 발열 문제
# 메모리 사용량 확인
free -h성능 디버깅
추론 속도가 기대에 미치지 못하는 경우 단계별로 병목을 파악해야 합니다. 먼저 단일 노드에서의 성능을 측정하여 기준선을 설정하고, 노드를 하나씩 추가하면서 성능 변화를 관찰합니다. Distributed Llama의 상세 로그에서 각 토큰 생성 시의 예측 시간(Pred)과 동기화 시간(Sync)을 확인할 수 있습니다. 동기화 시간이 예측 시간보다 현저히 긴 경우 네트워크 병목이 있는 것이며, 네트워크 설정을 점검해야 합니다. CPU 사용률이 100% 미만인 경우에는 스레드 수 설정이나 다른 시스템 제한을 확인해야 합니다.
토크나이저 경고 이해
벤치마크 로그에서 "Tokenizer vocab size (151669) does not match the model vocab size (151936)"라는 경고가 표시됩니다. 이는 토크나이저의 어휘 크기와 모델의 어휘 크기가 약간 불일치함을 나타냅니다. 이 경고는 대부분의 경우 무시해도 되지만, 특수 토큰 처리에서 문제가 발생할 수 있으므로 주의가 필요합니다. 모델과 토크나이저 버전이 일치하는지 확인하고, 가능하면 공식 소스에서 다운로드한 파일을 사용하는 것이 좋습니다.
10. 결론 및 향후 전망
핵심 요약
이번 글에서는 Distributed Llama를 사용하여 4대의 라즈베리 파이 5 클러스터에서 Qwen3-30B MoE 모델을 실행하는 방법을 상세히 살펴보았습니다. 분산 클러스터 방식은 13.04 tok/s의 추론 속도를 달성하여, 단일 노드 방식(8.03 tok/s) 대비 62% 향상된 성능을 보여주었습니다. 이는 저비용 SBC들을 연결하여 의미 있는 성능의 AI 추론 시스템을 구축할 수 있음을 입증합니다. 두 접근 방식은 각자의 장단점이 있으므로, 사용 환경과 요구사항에 따라 적절한 방식을 선택하면 됩니다.
엣지 AI의 미래
라즈베리 파이와 같은 저전력 장치에서 대규모 언어 모델을 실행할 수 있다는 것은 AI의 민주화 측면에서 중요한 의미를 갖습니다. 클라우드 의존 없이 개인 데이터를 로컬에서 처리할 수 있어 프라이버시가 보장되며, 네트워크 연결이 불안정한 환경에서도 AI 서비스를 제공할 수 있습니다. 양자화 기술과 분산 추론 기술의 발전으로 이러한 가능성은 계속 확대되고 있습니다. 향후 라즈베리 파이 6이나 더 강력한 SBC가 출시되면, 더 큰 모델을 더 빠른 속도로 실행할 수 있을 것입니다.
다음 단계
분산 LLM 클러스터 구축에 관심이 있다면, 먼저 단일 라즈베리 파이에서 작은 모델(Qwen3-0.6B 또는 Llama 3.2-1B)로 시작해 보시길 권장합니다.
기본적인 작동을 확인한 후 점진적으로 노드를 추가하고 더 큰 모델을 시도해 볼 수 있습니다. Distributed Llama의 GitHub 저장소에는 다양한 구성에 대한 벤치마크 결과가 공유되어 있으므로 참고하면 좋습니다. 또한 프로젝트의 Discussions 섹션에서 다른 사용자들의 경험과 팁을 얻을 수 있습니다. 엣지 AI의 세계는 빠르게 발전하고 있으며, 지금이 시작하기에 가장 좋은 시점입니다.
참고 자료
- Distributed Llama GitHub: https://github.com/b4rtaz/distributed-llama
- Qwen3-30B 벤치마크 Discussion: https://github.com/b4rtaz/distributed-llama/discussions/255
- GeekNews 원문: https://news.hada.io/topic?id=22984
- Distributed Llama v0.16.0 릴리즈 노트: https://github.com/b4rtaz/distributed-llama/releases/tag/v0.16.0
'AI 코딩' 카테고리의 다른 글
| Tailscale 완벽 가이드 (2편) - 설치부터 Zero Trust 네트워크 구축 (0) | 2026.02.07 |
|---|---|
| Tailscale 완벽 가이드 (1편) - 아키텍처 이해 (0) | 2026.02.07 |
| [라즈베리파이] 30B 파라미터 LLM 실시간 구동 (0) | 2026.02.01 |
| [라즈베리파이] Bookworm에서 Chrome 한글 입력 문제 해결하기 (0) | 2026.02.01 |
| [라즈베리파이] 4K모니터에서 CLI폰트 키우기 (0) | 2026.02.01 |



