라즈베리 파이에서 300억 파라미터 LLM 실시간 구동 - 엣지 AI의 새로운 지평
"6만원짜리 싱글보드 컴퓨터에서 300억 파라미터 AI 모델이 실시간으로 대화한다"
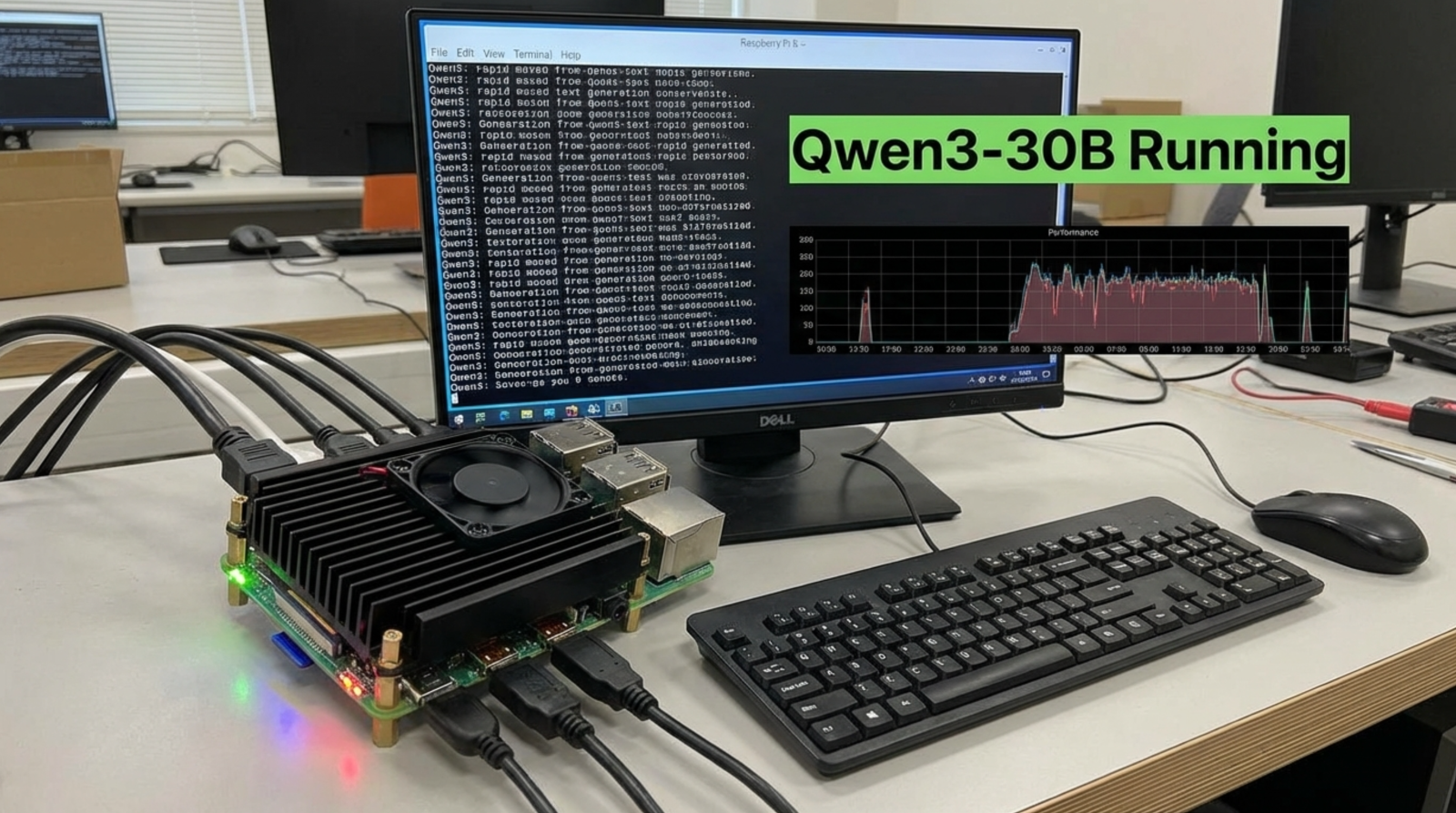
2025년을 지나 2026년, AI 기술의 민주화가 새로운 국면에 접어들었습니다. ByteShape 팀이 발표한 ShapeLearn 기술을 통해 Qwen3-30B-A3B 모델이 라즈베리 파이 5(16GB)에서 초당 8.03개의 토큰을 생성하며 실시간 대화가 가능해졌습니다. 이는 단순한 기술적 성취를 넘어, 클라우드 의존성에서 벗어난 진정한 엣지 AI 시대의 도래를 알리는 신호탄입니다.
본 글에서는 이 기술의 원리부터 실제 구축 방법, 그리고 활용 가능성까지 상세히 살펴보겠습니다.
목 차
1. 개요 및 배경
엣지 AI의 진화
지난 몇 년간 대규모 언어 모델(LLM)은 클라우드 기반 서비스가 당연시되어 왔습니다. GPT-4, Claude, Gemini와 같은 모델들은 수십억 개의 파라미터를 가지고 있으며, 이를 구동하기 위해서는 고성능 GPU 클러스터가 필수적이었습니다. 그러나 프라이버시 보호, 네트워크 지연 최소화, 오프라인 운영 등의 요구사항이 증가하면서 로컬 LLM 구동에 대한 관심이 급증하고 있습니다. 특히 IoT 디바이스, 스마트홈, 로봇공학 분야에서 저전력 엣지 디바이스에서의 AI 추론 능력은 핵심 경쟁력으로 부상하고 있습니다.
라즈베리 파이의 AI 가능성
라즈베리 파이 5는 2023년 출시 이후 ARM Cortex-A76 쿼드코어 프로세서(2.4GHz)와 최대 16GB LPDDR4X 메모리를 탑재하여 이전 세대 대비 약 3배의 성능 향상을 달성했습니다. 이러한 하드웨어 발전과 함께 llama.cpp와 같은 최적화된 추론 엔진의 등장으로, 이제 라즈베리 파이에서도 의미 있는 수준의 LLM 추론이 가능해졌습니다. 실제로 TinyLlama(1.1B)의 경우 초당 5-7개 토큰, Llama-3.2-3B 모델은 초당 4-6개 토큰의 생성 속도를 보여주고 있어, 간단한 대화나 코딩 어시스턴트 용도로 활용이 가능한 수준입니다.
ByteShape의 혁신 | 30B 모델의 실시간 구동
여기서 ByteShape 팀의 성과가 특별한 이유는 무려 300억 파라미터 규모의 모델을 라즈베리 파이에서 실시간으로 구동했다는 점입니다. 일반적으로 30B 모델은 최소 30GB 이상의 메모리가 필요하지만, ShapeLearn이라는 혁신적인 비트길이 학습 기법을 통해 모델 크기를 대폭 압축하면서도 94% 이상의 품질을 유지할 수 있었습니다. 이는 메모리 제약이 있는 엣지 디바이스에서 고성능 AI를 구현할 수 있는 새로운 가능성을 제시하며, 토론토 대학교 스핀오프 기업인 ByteShape의 기술력이 돋보이는 대목입니다.
2. Qwen3-30B-A3B 모델 아키텍처

Mixture-of-Experts (MoE) 구조
Qwen3-30B-A3B는 알리바바의 Qwen 팀이 개발한 최신 대규모 언어 모델로, 독특한 Mixture-of-Experts(MoE) 아키텍처를 채택하고 있습니다. 전체 300.5억 개의 파라미터를 보유하고 있지만, 실제 추론 시에는 33억 개의 파라미터만 활성화됩니다. 이러한 구조는 Dense 모델 대비 동일한 성능을 달성하면서도 연산량을 획기적으로 줄일 수 있어, 리소스가 제한된 환경에서 특히 유리합니다. 128개의 전문가(Expert) 네트워크 중 입력에 따라 8개만 선택적으로 활성화되는 이 방식은 마치 여러 분야의 전문가가 협력하는 것과 유사한 원리로 작동합니다.
모델 사양 상세
Qwen3-30B-A3B-Instruct-2507 모델의 핵심 사양은 다음과 같습니다.
먼저 레이어 수는 48개이며, 어텐션 헤드는 GQA(Grouped Query Attention) 방식으로 Query 32개, Key-Value 4개로 구성됩니다.
- 기본 컨텍스트 길이는 262,144 토큰을 지원하여 매우 긴 문서도 한 번에 처리할 수 있습니다.
- 또한 YaRN(Yet another RoPE N) 기법을 적용하면 최대 1백만 토큰까지 확장 가능합니다.
- 지원 언어는 100개 이상의 언어와 방언을 포괄하며, 한국어도 우수한 성능을 보여줍니다.
- 2507 버전은 Non-Thinking 모드로 최적화되어 빠른 응답 생성에 특화되어 있습니다.
MoE vs Dense 모델 비교
MoE 아키텍처의 장점을 더 명확히 이해하기 위해 Dense 모델과 비교해 보겠습니다. Dense 모델에서는 모든 파라미터가 매 추론마다 활성화되지만, MoE에서는 라우팅 메커니즘이 입력에 따라 적절한 전문가를 선택합니다. Qwen3-30B-A3B의 경우 30B 전체 파라미터 중 3.3B만 활성화되므로, 연산 효율이 약 9배 개선됩니다. 이는 동일한 하드웨어에서 더 큰 모델을 구동하거나, 동일 크기 모델을 더 빠르게 실행할 수 있음을 의미합니다. 특히 Qwen 팀의 벤치마크에 따르면, Qwen3-30B-A3B는 10배 더 많은 활성 파라미터를 가진 QwQ-32B 모델을 능가하는 성능을 보여주었습니다.
┌─────────────────────────────────────────────────────────────────┐
│ Qwen3-30B-A3B 모델 구조 │
├─────────────────────────────────────────────────────────────────┤
│ 총 파라미터: 30.5B 활성 파라미터: 3.3B │
│ 레이어 수: 48 전문가 수: 128 (활성: 8) │
│ 어텐션 헤드: Q=32, KV=4 컨텍스트: 262K (확장 시 1M) │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 입력 토큰 │
│ ↓ │
│ ┌───────────┐ │
│ │ Embedding │ │
│ └────┬──────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────┐ │
│ │ Transformer Block x48 │ │
│ │ ┌─────────────┐ ┌──────────────────┐ │ │
│ │ │ Attention │ → │ MoE FFN Layer │ │ │
│ │ │ (GQA) │ │ 8/128 Experts │ │ │
│ │ │ │ │ 활성화 │ │ │
│ │ └─────────────┘ └──────────────────┘ │ │
│ └─────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────┐ │
│ │ Output │ │
│ └─────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘graph TB
subgraph MoE["Mixture-of-Experts 아키텍처"]
Input[/"입력 토큰"/]
Router["라우터 네트워크"]
subgraph Experts["128개 전문가 네트워크"]
E1["Expert 1"]
E2["Expert 2"]
E3["Expert 3"]
E4["..."]
E5["Expert 8"]
E6["..."]
E7["Expert 128"]
style E1 fill:#4ADE80,stroke:#16A34A
style E2 fill:#4ADE80,stroke:#16A34A
style E3 fill:#4ADE80,stroke:#16A34A
style E5 fill:#4ADE80,stroke:#16A34A
style E4 fill:#E5E7EB,stroke:#9CA3AF
style E6 fill:#E5E7EB,stroke:#9CA3AF
style E7 fill:#E5E7EB,stroke:#9CA3AF
end
Combine["결과 결합"]
Output[/"출력 토큰"/]
end
Input --> Router
Router -->|"선택"| E1
Router -->|"선택"| E2
Router -->|"선택"| E3
Router -.->|"비활성"| E4
Router -->|"선택"| E5
Router -.->|"비활성"| E6
Router -.->|"비활성"| E7
E1 & E2 & E3 & E5 --> Combine
Combine --> Output
style Router fill:#818CF8,stroke:#4F46E5
style Combine fill:#818CF8,stroke:#4F46E5
style Input fill:#F3F4F6,stroke:#6B7280
style Output fill:#F3F4F6,stroke:#6B72803. ShapeLearn 비트길이 학습 기술
양자화의 기본 개념
딥러닝 모델의 가중치는 일반적으로 32비트 또는 16비트 부동소수점으로 저장됩니다. 양자화(Quantization)는 이러한 높은 정밀도의 가중치를 4비트, 3비트, 심지어 2비트와 같은 낮은 비트로 변환하여 모델 크기와 메모리 사용량을 줄이는 기법입니다. 예를 들어, 16비트에서 4비트로 양자화하면 모델 크기가 4배 감소합니다. 그러나 단순히 비트 수를 줄이면 정밀도 손실로 인해 모델 품질이 저하될 수 있으며, 이를 최소화하면서 효율적으로 압축하는 것이 핵심 과제입니다. llama.cpp에서 사용하는 GGUF 포맷은 이러한 양자화된 모델을 효율적으로 저장하고 추론하기 위한 표준 형식입니다.
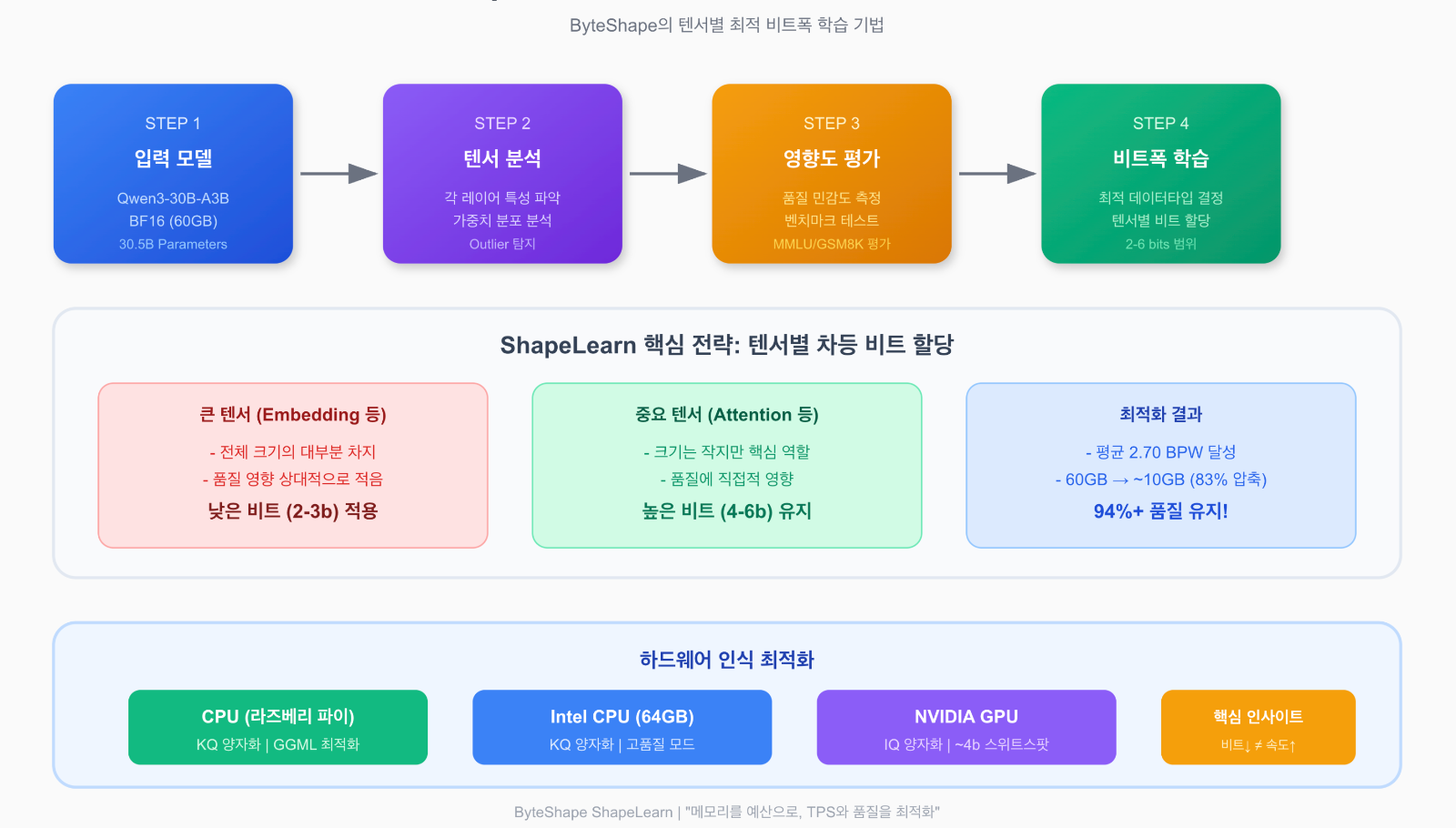
ShapeLearn의 혁신적 접근
기존 양자화 방식들(Unsloth, MagicQuant 등)은 대부분 획일적인 비트 할당 전략을 사용합니다. 즉, 모델의 모든 텐서에 동일하거나 유사한 비트폭을 적용합니다. 반면 ByteShape의 ShapeLearn은 각 텐서의 특성을 개별적으로 분석하여 최적의 비트폭을 학습합니다. 핵심 아이디어는 "품질에 미치는 영향이 적은 큰 텐서(예: 임베딩)는 낮은 비트로 강하게 압축하고, 품질에 중요한 작은 텐서는 높은 비트를 유지하여 정확도 손실을 최소화"하는 것입니다. 이를 통해 동일한 파일 크기에서 더 높은 품질을, 또는 동일한 품질에서 더 작은 크기를 달성할 수 있습니다.
하드웨어 인식 최적화
ShapeLearn의 또 다른 혁신은 하드웨어 특성을 고려한 최적화입니다. 흥미롭게도 llama.cpp 환경에서는 비트 수를 줄인다고 항상 속도가 빨라지지 않습니다. 이는 GPU와 CPU의 커널 구현 방식과 관련이 있습니다. 예를 들어, NVIDIA GPU는 32스레드 워프(warp) 단위로 작동하며, VRAM은 32바이트 정렬 블록 단위로 읽습니다. 따라서 더 작은 데이터라도 동일한 대역폭을 사용하게 되고, 낮은 비트폭은 추가적인 디코딩 오버헤드를 발생시킬 수 있습니다. ByteShape는 이러한 하드웨어 특성을 고려하여 RTX 5090에서는 iq4_xs가 54μs에 처리되는 반면 iq3_xxs는 62μs가 걸리는 현상(25% 크기 감소가 오히려 13% 속도 저하를 유발)을 발견하고, 이를 최적화에 반영했습니다.
CPU/GPU 별 최적화 모델
ByteShape는 타겟 하드웨어에 따라 두 가지 유형의 양자화 모델을 제공합니다. CPU 환경에서는 KQ(K-Quant) 양자화가 GGML 커널 효율성 덕분에 더 나은 성능을 보여주며, KQ-2, KQ-5, KQ-7 등의 라벨로 제공됩니다. GPU 환경(특히 NVIDIA)에서는 IQ(I-Quant) 양자화가 더 높은 처리량을 제공하며, KQ와 IQ를 혼합한 하이브리드 접근 방식으로 최적의 성능을 달성합니다. 이러한 하드웨어 인식 최적화는 동일한 모델이라도 타겟 디바이스에 따라 서로 다른 양자화 전략을 적용함으로써 최상의 TPS/품질 트레이드오프를 달성하게 합니다.
flowchart TB
subgraph Input["입력 모델"]
A[("Qwen3-30B-A3B\nBF16 원본\n~60GB")]
end
subgraph ShapeLearn["ShapeLearn 비트길이 학습"]
direction TB
B["텐서 분석\n각 레이어/텐서 특성 파악"]
C["영향도 평가\n품질에 미치는 영향 측정"]
D["비트폭 학습\n최적 데이터타입 결정"]
E["하드웨어 인식\n타겟 디바이스 최적화"]
B --> C --> D --> E
end
subgraph Strategy["비트 할당 전략"]
F["큰 텐서 (임베딩)\n→ 낮은 비트 (2-3b)"]
G["작은/중요 텐서\n→ 높은 비트 (4-6b)"]
H["CPU용: KQ 양자화"]
I["GPU용: IQ 양자화"]
end
subgraph Output["출력 모델"]
J[("ByteShape GGUF\n~10GB (Q3_K_S)")]
K["94%+ 품질 유지"]
L["8+ TPS on Pi 5"]
end
A --> B
E --> F & G
F & G --> H & I
H & I --> J
J --> K & L
style Input fill:#E0E7FF,stroke:#4F46E5,stroke-width:2px
style ShapeLearn fill:#F5F3FF,stroke:#6366F1,stroke-width:2px
style Strategy fill:#EEF2FF,stroke:#818CF8,stroke-width:2px
style Output fill:#E0E7FF,stroke:#4F46E5,stroke-width:2px4. 성능 벤치마크 분석
라즈베리 파이 5 성능
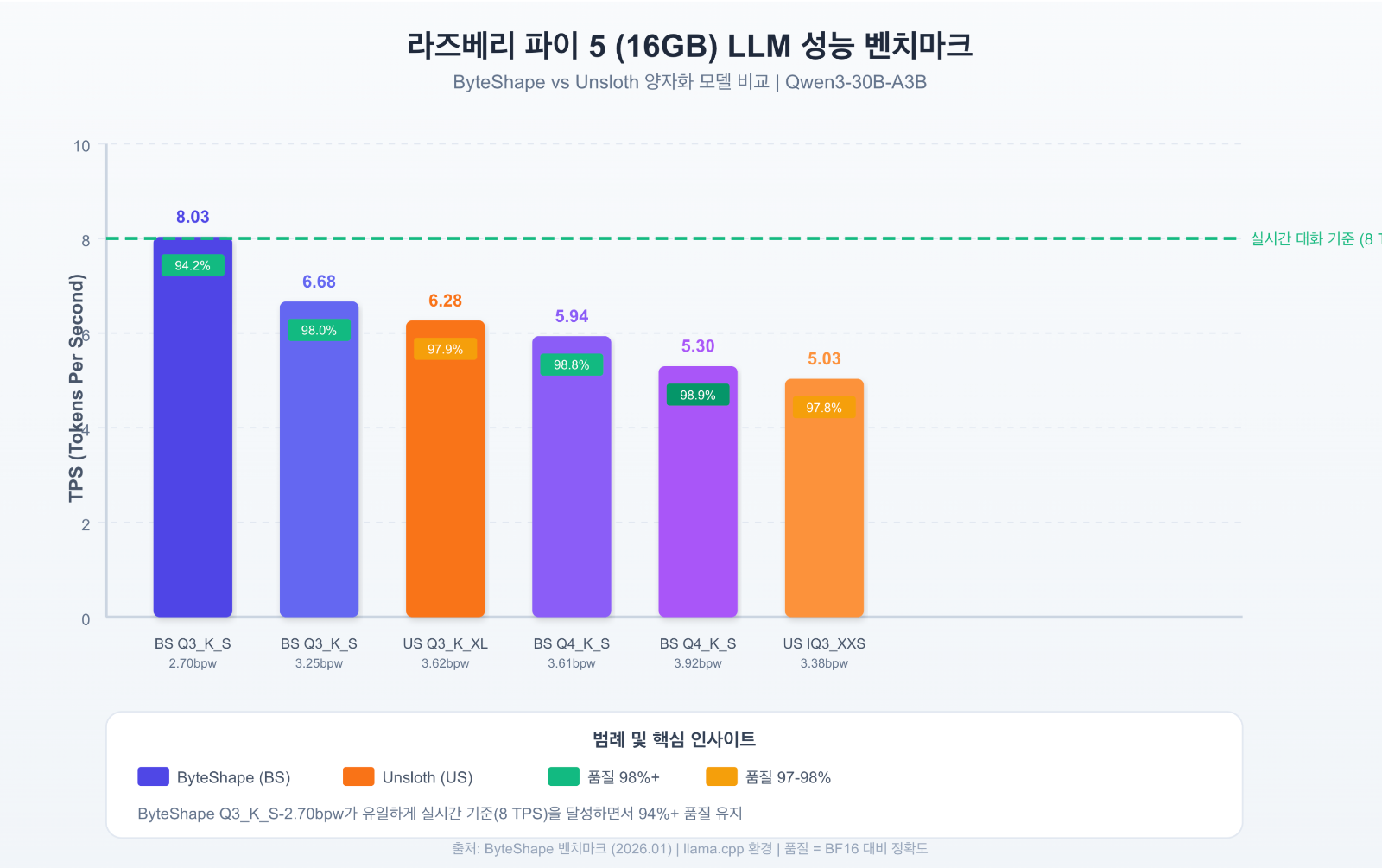
ByteShape 팀의 벤치마크 결과, 라즈베리 파이 5(16GB)에서 Qwen3-30B-A3B 모델은 놀라운 성능을 보여주었습니다. 가장 추천되는 Q3_K_S-2.70bpw [KQ-2] 모델은 2.70 BPW(Bits Per Weight)로 압축되어 초당 8.03개의 토큰을 생성하며, BF16 원본 대비 94.18%의 품질을 유지합니다. 이 속도는 일반적인 읽기 속도를 상회하여 체감상 실시간 대화가 가능한 수준입니다. 정확도를 우선시하는 경우 Q4_K_S-3.92bpw [KQ-7] 모델은 98.86% 정확도에 5.30 TPS를 달성하여, Unsloth의 동급 모델 대비 최대 1.87배 낮은 오류율을 보여주었습니다.
경쟁 솔루션 대비 우위
ByteShape 모델은 기존 양자화 솔루션들과 비교하여 전반적으로 우수한 성능을 보여줍니다. 라즈베리 파이 환경에서 Unsloth의 여러 모델(UD-IQ3_XXS, UD-Q3_K_XL 등)과 비교했을 때, ByteShape는 동일 품질 수준에서 더 높은 TPS를, 또는 동일 TPS에서 더 높은 품질을 달성했습니다. 특히 주목할 점은 MagicQuant와 Unsloth의 많은 모델들이 메모리 제약으로 인해 라즈베리 파이에서 아예 실행되지 않는 반면, ByteShape 모델은 메모리 예산 내에서 최적화되어 안정적으로 구동된다는 것입니다. 이는 ShapeLearn이 단순히 품질뿐 아니라 실제 배포 가능성까지 고려한 접근법임을 보여줍니다.
GPU 환경 성능 (RTX 5090/4080)
고성능 GPU 환경에서도 ByteShape의 장점은 두드러집니다.
RTX 5090(32GB VRAM)에서는 약 4비트 근처가 "스위트 스팟"으로 확인되었으며, Unsloth, MagicQuant, ByteShape 모두 302-303 TPS 수준의 비슷한 처리량을 보였습니다. 그러나 정확도 우선 시나리오에서 ByteShape의 IQ4_XS-4.67bpw [IQ-8] 모델은 272.98 TPS에서 99.75% 정확도를 달성하여 최고 정확도 타이틀을 차지했습니다.
RTX 4080(16GB VRAM)에서는 VRAM 제약으로 4비트 모델이 불가능한 상황에서 ByteShape의 IQ4_XS-3.87bpw [IQ-6]가 214.81 TPS에서 98.66% 정확도를 달성하여, Unsloth 대비 1.59배 낮은 오류율과 9.4% 높은 TPS를 기록했습니다.
성능 비교 요약
| 디바이스 | 모델 | BPW | TPS | 품질(BF16대비) | 비고 |
| 라즈베리 파이 5 | Q3_K_S-2.70bpw [KQ-2] | 2.70 | 8.03 | 94.18% | 실시간 대화 추천 |
| 라즈베리 파이 5 | Q4_K_S-3.92bpw [KQ-7] | 3.92 | 5.30 | 98.86% | 정확도 우선 |
| Intel i7 (64GB) | IQ4_XS-4.67bpw [KQ-9] | 4.67 | - | 99.75% | 최고 품질 |
| RTX 5090 (32GB) | IQ4_XS-4.67bpw [IQ-8] | 4.67 | 272.98 | 99.75% | GPU 최적화 |
| RTX 4080 (16GB) | IQ4_XS-3.87bpw [IQ-6] | 3.87 | 214.81 | 98.66% | VRAM 제약 환경 |
flowchart LR
subgraph Hardware["하드웨어별 최적화"]
direction TB
subgraph Pi["라즈베리 파이 5 (16GB)"]
P1["Q3_K_S-2.70bpw"]
P2["8.03 TPS"]
P3["94.18% 품질"]
end
subgraph CPU["Intel i7 (64GB)"]
C1["IQ4_XS-4.67bpw"]
C2["26+ TPS"]
C3["99.75% 품질"]
end
subgraph GPU["RTX 5090 (32GB)"]
G1["IQ4_XS-4.67bpw"]
G2["272.98 TPS"]
G3["99.75% 품질"]
end
end
style Pi fill:#D1FAE5,stroke:#059669,stroke-width:2px
style CPU fill:#A7F3D0,stroke:#047857,stroke-width:2px
style GPU fill:#6EE7B7,stroke:#065F46,stroke-width:2px5. 라즈베리 파이 5 환경 구축
하드웨어 요구사항
라즈베리 파이에서 30B 규모의 LLM을 구동하기 위해서는 반드시 16GB RAM 모델의 라즈베리 파이 5가 필요합니다. 8GB 모델로는 메모리 부족으로 모델 로딩이 불가능합니다. 추가로 권장되는 하드웨어 구성은 다음과 같습니다. 먼저 고속 microSD 카드(A2 등급) 또는 NVMe SSD를 USB 어댑터로 연결하면 모델 로딩 시간을 크게 단축할 수 있습니다. 액티브 쿨링 솔루션(쿨러 팬 또는 히트싱크)은 장시간 추론 시 발생하는 열로 인한 쓰로틀링을 방지하기 위해 필수입니다. 안정적인 전원 공급을 위해 공식 27W USB-C 전원 어댑터 사용을 권장합니다.
운영체제 설치
라즈베리 파이 OS 64비트 버전을 설치해야 합니다. 32비트 버전에서는 메모리 주소 제한으로 인해 대용량 모델을 로드할 수 없습니다. 공식 Raspberry Pi Imager를 사용하여 최신 64비트 OS를 microSD 카드에 설치하는 것이 가장 간편한 방법입니다. 설치 과정에서 SSH 활성화, Wi-Fi 설정, 사용자 계정 설정을 미리 구성해두면 헤드리스(모니터 없이) 환경에서도 원격 접속이 가능합니다. 초기 부팅 후에는 시스템 업데이트를 수행하여 최신 커널과 펌웨어를 적용하는 것이 안정성과 성능 면에서 유리합니다.
시스템 업데이트 및 기본 패키지 설치
운영체제 설치 후 터미널에서 다음 명령어들을 순차적으로 실행하여 시스템을 최신 상태로 업데이트하고 필요한 개발 도구들을 설치합니다.
# 시스템 패키지 목록 업데이트 및 전체 업그레이드
sudo apt update && sudo apt upgrade -y
# 개발 도구 및 필수 라이브러리 설치
sudo apt install -y git build-essential cmake python3-pip libcurl4-openssl-dev
# (선택) 성능 모니터링 도구 설치
sudo apt install -y htop iotop스왑 메모리 설정
16GB RAM 모델이라도 대용량 모델 로딩 시 메모리 부족 상황이 발생할 수 있습니다. 이를 대비하여 스왑 파일을 설정하면 안정성을 높일 수 있습니다. 다만 스왑 사용 시 성능이 저하될 수 있으므로 충분한 RAM이 확보된 상태에서는 스왑 의존도를 최소화하는 것이 바람직합니다. 아래 명령어로 4GB 스왑 파일을 생성하고 활성화할 수 있습니다.
# 기존 스왑 비활성화
sudo dphys-swapfile swapoff
# 스왑 파일 크기 설정 (MB 단위, 4096 = 4GB)
sudo sed -i 's/CONF_SWAPSIZE=.*/CONF_SWAPSIZE=4096/' /etc/dphys-swapfile
# 스왑 파일 재설정 및 활성화
sudo dphys-swapfile setup
sudo dphys-swapfile swapon
# 스왑 상태 확인
free -h6. llama.cpp 설치 및 설정
llama.cpp 소개
llama.cpp는 Georgi Gerganov가 개발한 순수 C/C++ 기반의 LLM 추론 엔진으로, CPU와 GPU 모두에서 효율적인 추론을 지원합니다. 특히 양자화된 GGUF 포맷 모델을 네이티브로 지원하며, 외부 의존성이 최소화되어 임베디드 환경에서도 쉽게 빌드할 수 있습니다. llama.cpp는 다양한 백엔드(OpenBLAS, cuBLAS, Vulkan, Metal 등)를 지원하여 하드웨어 가속을 활용할 수 있으며, 라즈베리 파이에서는 주로 CPU 기반의 OpenBLAS 또는 기본 GGML 백엔드를 사용합니다. 최근에는 서버 모드, 웹 UI, Python 바인딩 등 다양한 기능이 추가되어 활용 범위가 넓어지고 있습니다.
소스 코드 클론 및 빌드
최신 llama.cpp를 GitHub에서 클론하여 빌드합니다. CMake 기반 빌드 시스템을 사용하며, 라즈베리 파이의 모든 CPU 코어를 활용하여 컴파일 시간을 단축할 수 있습니다. 빌드 과정은 라즈베리 파이 5 기준으로 약 5-10분 정도 소요됩니다.
# llama.cpp 저장소 클론
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# CMake 빌드 디렉토리 생성 및 구성
cmake -B build -DCMAKE_BUILD_TYPE=Release
# 병렬 빌드 실행 (모든 CPU 코어 활용)
cmake --build build --config Release -j$(nproc)
# 빌드 결과 확인
ls -la build/bin/주요 실행 파일 설명
빌드가 완료되면 build/bin/ 디렉토리에 여러 실행 파일이 생성됩니다.
- llama-cli는 커맨드라인 인터페이스로 직접 프롬프트를 입력하고 응답을 받을 수 있는 기본 도구입니다.
- llama-server는 HTTP API 서버로, REST API를 통해 외부 애플리케이션에서 LLM을 호출할 수 있게 해줍니다.
- llama-bench는 모델의 성능을 측정하는 벤치마크 도구로, TPS와 메모리 사용량 등을 확인할 수 있습니다.
- llama-quantize는 모델 양자화 도구로, 원본 모델을 다양한 양자화 레벨로 변환할 때 사용합니다.
우리는 주로 llama-cli와 llama-server를 사용하게 됩니다.
환경 변수 및 PATH 설정
편의를 위해 llama.cpp 바이너리를 시스템 PATH에 추가하거나 심볼릭 링크를 생성할 수 있습니다. 또한 모델 파일을 저장할 디렉토리를 생성하여 체계적으로 관리하는 것이 좋습니다.
# 모델 저장 디렉토리 생성
mkdir -p ~/models
# (선택) 바이너리를 로컬 bin 디렉토리에 링크
mkdir -p ~/.local/bin
ln -s $(pwd)/build/bin/llama-cli ~/.local/bin/
ln -s $(pwd)/build/bin/llama-server ~/.local/bin/
# PATH에 추가 (영구 적용을 위해 .bashrc에 추가)
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc7. ByteShape 모델 다운로드 및 실행
Hugging Face에서 모델 다운로드
ByteShape의 최적화된 GGUF 모델은 Hugging Face에서 다운로드할 수 있습니다.
라즈베리 파이 5(16GB)에서 권장되는 모델은 Q3_K_S-2.70bpw [KQ-2]로, 실시간 대화가 가능한 8+ TPS의 속도를 제공하면서 94% 이상의 품질을 유지합니다. 파일 크기는 약 10GB 내외이므로 다운로드에 시간이 소요될 수 있습니다. wget 또는 curl을 사용하여 직접 다운로드하거나, huggingface-cli를 사용할 수 있습니다.
# 모델 디렉토리로 이동
cd ~/models
# wget을 사용한 모델 다운로드 (예시 - 실제 파일명은 Hugging Face에서 확인)
wget https://huggingface.co/byteshape/Qwen3-30B-A3B-Instruct-2507-GGUF/resolve/main/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf
# 또는 huggingface-cli 사용 (권장)
pip install huggingface_hub
huggingface-cli download byteshape/Qwen3-30B-A3B-Instruct-2507-GGUF \
Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf \
--local-dir .기본 추론 실행
모델 다운로드가 완료되면 llama-cli를 사용하여 기본적인 추론을 실행해볼 수 있습니다. 라즈베리 파이의 4개 CPU 코어를 모두 활용하도록 스레드 수를 지정하고, 컨텍스트 크기는 메모리 상황에 맞게 조절합니다. 처음 실행 시 모델 로딩에 1-2분 정도 소요될 수 있습니다.
# 기본 추론 테스트
cd ~/llama.cpp
./build/bin/llama-cli \
-m ~/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf \
-p "라즈베리 파이에서 AI를 실행하는 방법을 간단히 설명해주세요." \
-n 256 \
-t 4 \
-c 4096
# 파라미터 설명:
# -m : 모델 파일 경로
# -p : 프롬프트 (질문)
# -n : 생성할 최대 토큰 수
# -t : CPU 스레드 수 (라즈베리 파이 5는 4코어)
# -c : 컨텍스트 크기 (메모리 사용량에 영향)대화형 모드 실행
일회성 질문이 아닌 지속적인 대화를 위해서는 인터랙티브 모드를 사용합니다. 이 모드에서는 채팅 형식으로 여러 번의 질문과 응답을 주고받을 수 있으며, 대화 히스토리가 컨텍스트에 유지됩니다. --color 옵션을 추가하면 사용자 입력과 AI 응답이 색상으로 구분되어 가독성이 향상됩니다.
# 대화형 모드 실행
./build/bin/llama-cli \
-m ~/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf \
-t 4 \
-c 4096 \
--interactive \
--color \
--temp 0.7 \
--top-p 0.9 \
--repeat-penalty 1.1
# 추가 파라미터 설명:
# --interactive : 대화형 모드 활성화
# --color : 색상 출력 활성화
# --temp : 온도 (낮을수록 결정적, 높을수록 창의적)
# --top-p : 누클레우스 샘플링 확률
# --repeat-penalty : 반복 억제 계수API 서버 실행
외부 애플리케이션에서 LLM을 활용하려면 HTTP API 서버를 실행합니다.
llama-server는 OpenAI API와 호환되는 엔드포인트를 제공하여 기존 OpenAI 클라이언트 라이브러리를 그대로 사용할 수 있습니다. 서버 실행 후 http://[라즈베리파이IP]:8080으로 접속하면 내장 웹 UI도 사용할 수 있습니다.
# API 서버 실행
./build/bin/llama-server \
-m ~/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf \
-t 4 \
-c 4096 \
--host 0.0.0.0 \
--port 8080
# 다른 터미널에서 API 테스트
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen",
"messages": [
{"role": "user", "content": "안녕하세요, 자기소개를 해주세요."}
],
"max_tokens": 256
}'8. 실전 활용 예시
Python을 이용한 챗봇 구현
Python에서 llama-cpp-python 바인딩을 사용하면 더욱 유연한 애플리케이션을 개발할 수 있습니다. 이 바인딩은 llama.cpp를 Python에서 직접 호출할 수 있게 해주며, 별도의 서버 프로세스 없이도 모델을 로드하고 추론을 실행할 수 있습니다. 아래는 간단한 대화형 챗봇 구현 예시입니다.
# chatbot.py - 라즈베리 파이 AI 챗봇
from llama_cpp import Llama
# 모델 로드 (초기 로딩에 1-2분 소요)
print("모델을 로딩 중입니다. 잠시 기다려주세요...")
llm = Llama(
model_path="/home/pi/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf",
n_threads=4, # CPU 스레드 수
n_ctx=4096, # 컨텍스트 크기
verbose=False # 로그 출력 비활성화
)
print("모델 로딩 완료!\n")
# 대화 히스토리 초기화
messages = []
# 시스템 프롬프트 설정
system_prompt = """당신은 라즈베리 파이에서 실행되는 친절한 AI 어시스턴트입니다.
한국어로 자연스럽게 대화하며, 간결하고 명확한 답변을 제공합니다."""
print("=== 라즈베리 파이 AI 챗봇 ===")
print("'종료'를 입력하면 대화를 종료합니다.\n")
while True:
# 사용자 입력 받기
user_input = input("사용자: ")
if user_input.strip().lower() in ['종료', 'quit', 'exit']:
print("대화를 종료합니다. 안녕히 가세요!")
break
# 메시지 히스토리에 사용자 입력 추가
messages.append({"role": "user", "content": user_input})
# 프롬프트 구성
prompt = f"<|system|>\n{system_prompt}<|end|>\n"
for msg in messages:
role = msg["role"]
content = msg["content"]
prompt += f"<|{role}|>\n{content}<|end|>\n"
prompt += "<|assistant|>\n"
# 응답 생성
response = llm(
prompt,
max_tokens=512,
temperature=0.7,
top_p=0.9,
stop=["<|end|>", "<|user|>"],
echo=False
)
# 응답 추출 및 출력
assistant_response = response["choices"][0]["text"].strip()
print(f"AI: {assistant_response}\n")
# 히스토리에 AI 응답 추가
messages.append({"role": "assistant", "content": assistant_response})음성 인식 연동 (Whisper + LLM)
라즈베리 파이에서 음성 기반 AI 어시스턴트를 구현하면 진정한 로컬 AI 비서를 만들 수 있습니다. OpenAI의 Whisper 모델(또는 faster-whisper)을 사용하여 음성을 텍스트로 변환하고, Qwen 모델로 응답을 생성한 후, TTS(Text-to-Speech)로 음성 출력하는 파이프라인을 구성할 수 있습니다. 다만 라즈베리 파이의 리소스 제약 상 Whisper의 tiny 또는 base 모델을 사용하는 것이 현실적입니다.
# voice_assistant.py - 음성 AI 어시스턴트 (개념 코드)
import whisper
from llama_cpp import Llama
import sounddevice as sd
import numpy as np
from TTS.api import TTS # Coqui TTS 또는 pyttsx3 사용 가능
# 모델 초기화
print("음성 인식 모델 로딩...")
whisper_model = whisper.load_model("tiny") # 라즈베리 파이용 경량 모델
print("언어 모델 로딩...")
llm = Llama(
model_path="/home/pi/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf",
n_threads=4,
n_ctx=2048
)
print("TTS 모델 로딩...")
tts = TTS(model_name="tts_models/ko/cv/vits") # 한국어 TTS
def record_audio(duration=5, sample_rate=16000):
"""마이크로 음성 녹음"""
print("🎤 듣고 있습니다...")
audio = sd.rec(int(duration * sample_rate),
samplerate=sample_rate, channels=1, dtype='float32')
sd.wait()
return np.squeeze(audio)
def speech_to_text(audio):
"""음성을 텍스트로 변환"""
result = whisper_model.transcribe(audio, language="ko")
return result["text"]
def generate_response(text):
"""LLM으로 응답 생성"""
prompt = f"사용자: {text}\nAI 어시스턴트:"
response = llm(prompt, max_tokens=256, stop=["\n사용자:"])
return response["choices"][0]["text"].strip()
def text_to_speech(text):
"""텍스트를 음성으로 변환하여 재생"""
tts.tts_to_file(text=text, file_path="response.wav")
# 오디오 재생 코드 (pygame 또는 sounddevice 사용)
# 메인 루프
print("\n=== 음성 AI 어시스턴트 시작 ===")
print("말씀하시면 듣고 응답합니다. Ctrl+C로 종료합니다.\n")
while True:
try:
audio = record_audio()
user_text = speech_to_text(audio)
print(f"인식된 음성: {user_text}")
response = generate_response(user_text)
print(f"AI 응답: {response}")
text_to_speech(response)
except KeyboardInterrupt:
print("\n음성 어시스턴트를 종료합니다.")
break스마트홈 제어 시스템
Home Assistant와 연동하여 음성 또는 텍스트 명령으로 스마트홈 기기를 제어하는 시스템을 구축할 수 있습니다. LLM이 자연어 명령을 해석하여 적절한 Home Assistant API 호출로 변환하는 방식입니다. 예를 들어 "거실 불 꺼줘"라는 명령을 받으면 light.turn_off 서비스를 호출하는 JSON을 생성합니다.
# smart_home.py - 스마트홈 AI 제어
import requests
from llama_cpp import Llama
# Home Assistant 설정
HA_URL = "http://homeassistant.local:8123"
HA_TOKEN = "your-long-lived-access-token"
# 시스템 프롬프트 - LLM이 HA 명령을 생성하도록 지시
SYSTEM_PROMPT = """당신은 스마트홈 제어 AI입니다.
사용자의 자연어 명령을 Home Assistant API 호출로 변환합니다.
응답은 반드시 다음 JSON 형식만 출력하세요:
{"service": "서비스명", "entity_id": "엔티티ID", "data": {}}
사용 가능한 기기:
- light.living_room: 거실 조명
- light.bedroom: 침실 조명
- climate.ac: 에어컨
- switch.tv: TV 전원
예시:
입력: "거실 불 켜줘"
출력: {"service": "light.turn_on", "entity_id": "light.living_room", "data": {}}
입력: "에어컨 25도로 설정해"
출력: {"service": "climate.set_temperature", "entity_id": "climate.ac", "data": {"temperature": 25}}
"""
llm = Llama(
model_path="/home/pi/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf",
n_threads=4,
n_ctx=2048
)
def parse_command(user_input):
"""자연어 명령을 HA 명령으로 변환"""
prompt = f"{SYSTEM_PROMPT}\n\n입력: {user_input}\n출력:"
response = llm(prompt, max_tokens=100, temperature=0.1)
return response["choices"][0]["text"].strip()
def execute_ha_command(command_json):
"""Home Assistant API 호출"""
import json
try:
cmd = json.loads(command_json)
url = f"{HA_URL}/api/services/{cmd['service'].replace('.', '/')}"
headers = {"Authorization": f"Bearer {HA_TOKEN}"}
payload = {"entity_id": cmd["entity_id"], **cmd.get("data", {})}
response = requests.post(url, json=payload, headers=headers)
return response.status_code == 200
except Exception as e:
print(f"명령 실행 오류: {e}")
return False
# 사용 예시
user_command = "거실 조명을 50% 밝기로 켜줘"
ha_command = parse_command(user_command)
print(f"생성된 명령: {ha_command}")
if execute_ha_command(ha_command):
print("명령이 성공적으로 실행되었습니다.")
else:
print("명령 실행에 실패했습니다.")활용 시나리오 아키텍처
┌─────────────────────────────────────────────────────────────────────────┐
│ 라즈베리 파이 AI 활용 시나리오 │
├─────────────────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 음성 입력 │ │ 텍스트 입력 │ │ 센서 데이터 │ │
│ │ (Whisper) │ │ (Chat UI) │ │ (GPIO/IoT) │ │
│ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │
│ └──────────────────┼──────────────────┘ │
│ ↓ │
│ ┌─────────────────────┐ │
│ │ 라즈베리 파이 5 │ │
│ │ (16GB RAM) │ │
│ │ ┌───────────────┐ │ │
│ │ │ Qwen3-30B │ │ │
│ │ │ (ByteShape) │ │ │
│ │ │ llama.cpp │ │ │
│ │ └───────────────┘ │ │
│ └─────────┬───────────┘ │
│ ↓ │
│ ┌──────────────────┼──────────────────┐ │
│ ↓ ↓ ↓ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 음성 출력 │ │ 스마트홈 제어 │ │ API 응답 │ │
│ │ (TTS) │ │(Home Assist)│ │ (REST) │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
│ ┌────────────────────────────────────────────────────────────────────┐ │
│ │ 활용 사례 │ │
│ │ • 오프라인 개인 비서 (프라이버시 보장) │ │
│ │ • 코딩 어시스턴트 (로컬 개발 환경) │ │
│ │ • 교육용 AI 튜터 (학교/학원) │ │
│ │ • 스마트홈 허브 (자연어 제어) │ │
│ │ • 로봇/드론 자율 판단 (엣지 AI) │ │
│ │ • 키오스크/안내 시스템 │ │
│ └────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────┘sequenceDiagram
participant User as 사용자
participant Voice as Whisper<br/>(음성 인식)
participant LLM as Qwen3-30B<br/>(ByteShape)
participant HA as Home Assistant
participant Device as 스마트 기기
User->>Voice: "거실 불 켜줘"
Voice->>LLM: 텍스트 변환
LLM->>LLM: 자연어 해석
LLM->>HA: API 호출 생성<br/>{"service": "light.turn_on"}
HA->>Device: 제어 명령
Device-->>User: 조명 켜짐
LLM-->>User: "거실 조명을 켰습니다"9. 최적화 팁 및 문제 해결
메모리 최적화
라즈베리 파이에서 대용량 모델을 구동할 때 메모리 관리는 매우 중요합니다.
먼저 불필요한 백그라운드 서비스를 비활성화하여 가용 RAM을 확보해야 합니다. GUI 환경보다는 CLI 환경(라이트 버전 OS)을 사용하면 약 500MB-1GB의 메모리를 절약할 수 있습니다. 컨텍스트 크기(-c 옵션)를 줄이면 메모리 사용량이 감소하지만, 대화 히스토리 길이도 제한됩니다. 일반적인 대화에는 2048-4096 정도면 충분하며, 문서 분석 등 긴 입력이 필요한 경우에만 더 큰 값을 사용합니다. mmap 옵션을 활성화하면 모델을 메모리에 완전히 로드하지 않고 필요한 부분만 읽어오므로 초기 로딩은 느리지만 메모리 사용이 효율적입니다.
# 현재 메모리 상태 확인
free -h
# 캐시 메모리 해제
sudo sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
# 메모리 최적화 옵션으로 실행
./build/bin/llama-cli \
-m ~/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf \
-t 4 \
-c 2048 \ # 컨텍스트 크기 축소
--mmap \ # 메모리 맵 사용
-p "테스트 프롬프트"발열 관리
장시간 추론 시 CPU 온도가 상승하면 쓰로틀링이 발생하여 성능이 저하됩니다. vcgencmd를 사용하여 실시간 온도를 모니터링하고, 70°C 이상이면 적극적인 냉각이 필요합니다. 액티브 쿨링(팬)을 사용하는 것이 가장 효과적이며, 공식 Active Cooler나 서드파티 쿨러를 장착하면 안정적인 장시간 운영이 가능합니다. 케이스 선택 시 통풍이 잘 되는 오픈 디자인이나 팬이 내장된 케이스를 권장합니다.
# CPU 온도 확인
vcgencmd measure_temp
# 실시간 온도 모니터링 (1초 간격)
watch -n 1 vcgencmd measure_temp
# CPU 주파수 확인 (쓰로틀링 여부)
vcgencmd measure_clock arm
# 쓰로틀링 상태 확인
vcgencmd get_throttled
# 0x0 = 정상, 그 외 값은 쓰로틀링 발생일반적인 오류 해결
대용량 모델 구동 시 자주 발생하는 오류와 해결 방법을 정리했습니다. 가장 흔한 문제는 메모리 부족으로 인한 세그멘테이션 폴트입니다. 이 경우 컨텍스트 크기를 줄이거나 더 작은 양자화 모델을 사용해야 합니다. Illegal instruction 오류는 64비트 OS가 아니거나 빌드 시 호환되지 않는 옵션을 사용한 경우 발생합니다. 모델 로딩 실패는 대부분 파일 경로 오류나 손상된 다운로드 파일이 원인입니다.
# 문제: Segmentation fault (메모리 부족)
# 해결: 컨텍스트 크기 축소 및 스왑 확인
./build/bin/llama-cli -m model.gguf -c 2048 -p "test"
# 문제: mmap: Cannot allocate memory
# 해결: 스왑 메모리 증가
sudo sed -i 's/CONF_SWAPSIZE=.*/CONF_SWAPSIZE=8192/' /etc/dphys-swapfile
sudo systemctl restart dphys-swapfile
# 문제: Model file not found
# 해결: 파일 경로 및 존재 여부 확인
ls -la ~/models/*.gguf
# 문제: Failed to load model
# 해결: 모델 파일 무결성 검사 (재다운로드)
sha256sum ~/models/Qwen3-30B-A3B-Instruct-2507-Q3_K_S-2.70bpw.gguf성능 튜닝 체크리스트
라즈베리 파이에서 최적의 LLM 성능을 얻기 위한 체크리스트입니다.
- 하드웨어 측면에서는 16GB RAM 모델 사용, 고속 스토리지(NVMe SSD 권장), 액티브 쿨링 장착을 확인합니다.
- 소프트웨어 측면에서는 64비트 OS 사용, 최신 커널 및 펌웨어 업데이트, 불필요한 서비스 비활성화를 점검합니다.
- llama.cpp 설정에서는 스레드 수(-t 4), 적절한 컨텍스트 크기, 배치 사이즈 조절 등을 최적화합니다.
- 마지막으로 모델 선택에서는 ByteShape의 KQ(CPU 최적화) 모델을 사용하고, 용도에 맞는 양자화 레벨을 선택합니다.
10. 향후 전망 및 결론
엣지 AI의 미래
라즈베리 파이에서 300억 파라미터 모델이 실시간으로 구동되는 것은 엣지 AI 기술의 중요한 이정표입니다.
이는 단순한 기술 데모를 넘어, 실제 프로덕션 환경에서 사용 가능한 수준에 도달했음을 의미합니다. 향후 몇 가지 방향으로 발전이 예상됩니다.
- 첫째, 더 효율적인 MoE 아키텍처와 양자화 기법의 발전으로 더 큰 모델도 엣지에서 구동 가능해질 것입니다.
- 둘째, 라즈베리 파이 6 등 차세대 하드웨어의 등장으로 성능이 더욱 향상될 것입니다.
- 셋째, NPU(신경망 처리 장치)가 통합된 엣지 디바이스가 보편화되면 AI 추론 성능이 획기적으로 개선될 것입니다.
ByteShape 기술의 의의
ByteShape의 ShapeLearn은 단순히 모델을 작게 만드는 것이 아니라, 하드웨어 특성을 고려한 지능적인 최적화를 수행합니다.
"메모리를 예산으로 보고, TPS와 품질을 최적화한다"는 철학은 실용적인 엣지 AI 배포에 매우 적합합니다. 특히 텐서별로 최적의 비트폭을 학습하는 접근법은 획일적인 양자화 대비 뛰어난 품질-효율 트레이드오프를 달성합니다. 토론토 대학교에서 시작된 이 스타트업의 기술이 오픈소스 커뮤니티에 공개되어 누구나 활용할 수 있다는 점도 고무적입니다.
실용적 활용 제언
라즈베리 파이에서 LLM을 실제로 활용하고자 하는 분들께 몇 가지 제언을 드립니다.
먼저 기대치를 현실적으로 설정해야 합니다. 8 TPS는 실시간 대화에 충분하지만, GPT-4나 Claude와 같은 클라우드 서비스의 응답 속도에는 미치지 못합니다. 그러나 프라이버시, 오프라인 운영, 비용 절감 측면에서는 명확한 장점이 있습니다.
용도에 맞는 모델을 선택하는 것도 중요합니다. 일상적인 대화나 간단한 질의응답에는 더 작은 모델(3B-8B)이 더 빠르고 실용적일 수 있습니다. 30B 모델은 복잡한 추론이나 전문적인 작업에 적합합니다.
결론
ByteShape의 ShapeLearn 기술을 통해 Qwen3-30B-A3B 모델이 라즈베리 파이 5에서 실시간으로 구동되는 것은 AI 민주화의 새로운 장을 열었습니다. 6만원짜리 싱글보드 컴퓨터에서 300억 파라미터의 언어 모델이 94% 이상의 품질로 실시간 대화가 가능하다는 것은 불과 1-2년 전만 해도 상상하기 어려웠던 일입니다. 이 기술은 개인 프라이버시를 중시하는 로컬 AI 어시스턴트, 인터넷 연결이 불안정한 환경에서의 AI 활용, 교육용 저비용 AI 실습 환경, 스마트홈 및 IoT 디바이스의 지능화, 그리고 로봇공학 분야의 온디바이스 AI 등 다양한 영역에서 새로운 가능성을 열어줍니다.
메모리를 "충분히 맞추는 예산"으로 보고 그 이후에는 속도와 품질의 균형을 최적화한다는 ByteShape의 철학은 리소스가 제한된 엣지 환경에서 AI를 배포하는 모든 개발자에게 중요한 교훈을 줍니다. 라즈베리 파이에서 시작하여 더 큰 CPU와 GPU 환경까지 동일한 원칙이 적용되며, "먼저 맞추고, 그다음 최적화하라"는 메시지는 실용적인 AI 시스템 설계의 핵심입니다.
참고 자료
공식 문서 및 저장소
- ByteShape 공식 블로그 - ShapeLearn 기술 및 벤치마크 상세
- ByteShape Hugging Face - 모델 다운로드
- Qwen 공식 블로그 - Qwen3 모델 소개
- llama.cpp GitHub - 추론 엔진
- 라즈베리 파이 공식 - 하드웨어 문서
추가 학습 자료
- GeekNews 원문 기사 - 한국어 요약 및 커뮤니티 의견
- Arm Learning Path - LLM on Raspberry Pi - 공식 튜토리얼
- Jeff Geerling - LLMs with eGPU - 외장 GPU 가속
'AI 코딩' 카테고리의 다른 글
| Tailscale 완벽 가이드 (1편) - 아키텍처 이해 (0) | 2026.02.07 |
|---|---|
| [라즈베리파이] 4대 클러스터로 Qwen3-30B 구동하기 (0) | 2026.02.02 |
| [라즈베리파이] Bookworm에서 Chrome 한글 입력 문제 해결하기 (0) | 2026.02.01 |
| [라즈베리파이] 4K모니터에서 CLI폰트 키우기 (0) | 2026.02.01 |
| Cloudflare Zero Trust VPN을 사용해 봅시다 (0) | 2026.01.25 |



