n8n에서 Browserless로 동적페이지 크롤링하기: HTTP Request 완벽 가이드
주요 키워드 : n8n 웹 크롤링, Browserless 사용법, 쿠팡 리뷰 크롤링, HTTP Request 노드, 헤드리스 브라우저, 봇 탐지 우회. 자동화 워크플로우

목 차
1. 왜 Browserless가 필요한가
웹 크롤링을 시도해 본 분이라면 누구나 한 번쯤 "봇 차단"이라는 벽에 부딪혀 본 경험이 있을 것입니다. 특히 쿠팡과 같은 대형 이커머스 플랫폼은 Akamai, Cloudflare 등의 봇 탐지 시스템을 적용하여 자동화된 접근을 강력하게 차단하고 있습니다. 단순한 HTTP Request만으로는 JavaScript로 렌더링되는 동적 콘텐츠를 가져올 수 없을 뿐만 아니라, 봇으로 탐지되어 접근 자체가 거부되는 경우가 대부분입니다. 이러한 한계를 극복하기 위해 등장한 것이 바로 Browserless입니다.
Browserless는 실제 브라우저 환경을 시뮬레이션하여 마치 사람이 웹사이트를 방문하는 것처럼 동작하게 해주는 헤드리스 브라우저 솔루션입니다. n8n 워크플로우 자동화 플랫폼과 결합하면, 복잡한 웹 크롤링 작업도 시각적인 노드 기반 인터페이스에서 손쉽게 구현할 수 있습니다. 이 글에서는 Docker로 설치된 Browserless를 n8n의 HTTP Request 노드에서 호출하는 방법을 상세히 알아보겠습니다.
2. Browserless란 무엇인가요?
Browserless의 핵심 개념
Browserless는 Chrome 브라우저를 헤드리스(화면 없이) 모드로 실행하고, 이를 API를 통해 원격으로 제어할 수 있게 해주는 도구입니다. 일반적인 HTTP Request가 단순히 HTML 문서만 가져오는 것과 달리, Browserless는 JavaScript 실행, 쿠키 처리, 세션 관리까지 실제 브라우저와 동일하게 수행합니다. 이를 통해 SPA(Single Page Application)나 동적으로 로딩되는 콘텐츠도 완벽하게 수집할 수 있습니다.
Browserless가 제공하는 주요 API 엔드포인트
Browserless는 다양한 용도에 맞는 여러 API 엔드포인트를 제공하며, 각각의 특성을 이해하면 상황에 맞는 최적의 방법을 선택할 수 있습니다. 아래 표에서 주요 엔드포인트의 특징과 사용 시나리오를 확인해 보시기 바랍니다.
| API 엔드포인트 | 설명 | 주요 사용 사례 |
| /content | 페이지의 HTML 콘텐츠 반환 | JavaScript 렌더링 후 HTML 추출 |
| /scrape | 구조화된 데이터 추출 | CSS 선택자 기반 데이터 수집 |
| /function | 커스텀 Puppeteer 스크립트 실행 | 복잡한 상호작용이 필요한 크롤링 |
| /screenshot | 페이지 스크린샷 캡처 | 시각적 모니터링, 썸네일 생성 |
| 페이지를 PDF로 변환 | 문서 아카이빙, 리포트 생성 |
Docker에서 Browserless 설치 확인
이미 Browserless가 Docker로 설치되어 있다면, 다음 명령어로 정상 동작 여부를 확인할 수 있습니다. 컨테이너가 실행 중인 상태에서 health check 엔드포인트에 접근하면 현재 상태 정보를 JSON 형식으로 반환받을 수 있습니다.
# Browserless 상태 확인
curl http://localhost:3000/json/version
# 정상 응답 예시
{
"Browser": "Chrome/120.0.0.0",
"Protocol-Version": "1.3",
"User-Agent": "Mozilla/5.0...",
"WebKit-Version": "537.36"
}
# 실제 응답 값
{
"Browser":"HeadlessChrome/121.0.6167.57",
"Protocol-Version":"1.3",
"User-Agent":"Mozilla/5.0 (X11; Linux aarch64) AppleWebKit/537.36 \
(KHTML, like Gecko) HeadlessChrome/121.0.6167.57 Safari/537.36",
"V8-Version":"12.1.285.20",
"WebKit-Version":"537.36 (@add6d6ffbc3a1c7e78cc15e6ba2dcb15208bedd5)",
"Debugger-Version":"add6d6ffbc3a1c7e78cc15e6ba2dcb15208bedd5",
"Puppeteer-Version":"21.9.0",
"webSocketDebuggerUrl":"ws://localhost:3000"
}3. cookie의 이해 및 웹크롤링에서의 중요성
쿠키(Cookie)란 무엇인가요?
웹 크롤링을 하다 보면 반드시 마주치게 되는 개념이 바로 쿠키(Cookie)입니다. 쿠키는 웹사이트가 사용자의 브라우저에 저장하는 작은 텍스트 파일로, 사용자를 식별하고 상태를 유지하는 데 사용됩니다. HTTP 프로토콜은 기본적으로 "무상태(Stateless)"이기 때문에, 서버는 각 요청이 누구로부터 왔는지 기억하지 못합니다. 쿠키는 이 문제를 해결하여 로그인 상태 유지, 장바구니 저장, 사용자 설정 기억 등의 기능을 가능하게 합니다.
쿠키가 없다면 여러분이 쿠팡에서 로그인한 후 다른 페이지로 이동할 때마다 다시 로그인해야 할 것입니다. 쿠키 덕분에 서버는 "이 요청은 아까 로그인한 그 사용자구나"라고 인식할 수 있습니다. 웹 크롤링 관점에서 쿠키는 실제 사용자처럼 행동하기 위한 핵심 열쇠입니다. 쿠키 없이 요청을 보내면 서버는 여러분을 처음 방문한 익명 사용자 또는 봇으로 인식하게 됩니다.
쿠키의 동작 원리
쿠키가 어떻게 동작하는지 이해하면 웹 크롤링에서 왜 쿠키가 중요한지 명확해집니다. 쿠키의 생명주기는 크게 세 단계로 나눌 수 있습니다.
1단계 | 쿠키 발급 (서버 → 브라우저)
사용자가 웹사이트에 처음 접속하면, 서버는 HTTP 응답 헤더의 Set-Cookie 필드를 통해 쿠키를 발급합니다. 이 쿠키에는 세션 ID, 사용자 식별자, 만료 시간 등의 정보가 담겨 있습니다.
HTTP/1.1 200 OK
Set-Cookie: PCID=17492184460720416178787; Path=/; Domain=.coupang.com; Expires=Sat, 20 Dec 2025 12:00:00 GMT
Set-Cookie: _abck=2697267D738094F03784D64B9F684B41~-1~YAAQd0g7F...; Path=/; Secure; HttpOnly2단계 | 쿠키 저장 (브라우저)
브라우저는 서버로부터 받은 쿠키를 로컬에 저장합니다. 각 쿠키는 도메인, 경로, 만료 시간 등의 속성을 가지며, 브라우저는 이 정보를 바탕으로 쿠키를 관리합니다.
3단계 | 쿠키 전송 (브라우저 → 서버)
이후 동일한 도메인에 요청을 보낼 때마다, 브라우저는 저장된 쿠키를 HTTP 요청 헤더의 Cookie 필드에 자동으로 포함시킵니다.
GET /next-api/review?productId=8096844330 HTTP/1.1
Host: www.coupang.com
Cookie: PCID=17492184460720416178787; _abck=2697267D738094F03784D64B9F684B41~-1~YAAQd0g7F...
쿠키의 주요 속성
쿠키는 단순한 키-값 쌍이 아니라 다양한 속성을 가지고 있습니다. 이 속성들을 이해하면 크롤링 시 어떤 쿠키가 중요하고, 어떤 쿠키가 문제를 일으킬 수 있는지 파악할 수 있습니다.
| 속성 | 설명 | 크롤링 시 고려사항 |
| Name=Value | 쿠키의 이름과 값 | 핵심 데이터, 반드시 포함해야 함 |
| Domain | 쿠키가 적용되는 도메인 | .coupang.com은 서브도메인 포함 |
| Path | 쿠키가 적용되는 경로 | /면 전체 사이트에 적용 |
| Expires/Max-Age | 쿠키 만료 시간 | 만료된 쿠키는 자동 삭제됨 |
| Secure | HTTPS에서만 전송 | HTTP로 요청 시 누락될 수 있음 |
| HttpOnly | JavaScript로 접근 불가 | 보안 목적, 크롤링에는 영향 없음 |
| SameSite | 크로스 사이트 요청 제한 | Strict/Lax/None 설정에 따라 동작 다름 |
Expires와 Max-Age의 차이
Expires는 쿠키가 만료되는 절대적인 날짜/시간을 지정하고, Max-Age는 쿠키가 유효한 상대적인 초 단위 시간을 지정합니다. 둘 다 설정되지 않으면 세션 쿠키가 되어 브라우저를 닫으면 삭제됩니다.
# 절대 시간 지정
Set-Cookie: token=abc123; Expires=Wed, 25 Dec 2025 12:00:00 GMT
# 상대 시간 지정 (1시간 = 3600초)
Set-Cookie: token=abc123; Max-Age=3600
웹크롤링에서 쿠키가 중요한 이유
인증 및 세션 유지
로그인이 필요한 페이지를 크롤링하려면 인증 쿠키가 필수입니다. 쿠팡의 경우 CSID, CT_AT, CPUSR_RL 등의 쿠키가 로그인 상태를 나타냅니다. 이 쿠키들 없이는 로그인 사용자만 볼 수 있는 데이터에 접근할 수 없습니다.
봇 탐지 우회
Akamai, Cloudflare 같은 봇 탐지 시스템은 쿠키를 활용하여 요청자를 식별합니다. _abck, bm_sz, bm_sv 등의 쿠키는 Akamai Bot Manager가 발급하는 것으로, 이 쿠키들이 없거나 유효하지 않으면 봇으로 판단되어 차단됩니다.
개인화된 콘텐츠 접근
쿠키에는 사용자의 지역, 언어, 선호도 정보가 포함될 수 있습니다. x-coupang-target-market=KR 같은 쿠키는 한국 시장용 콘텐츠를 제공받기 위해 필요합니다.
요청의 연속성 증명
서버는 쿠키를 통해 요청들이 하나의 연속된 세션에서 온 것인지 판단합니다. 쿠팡 리뷰 API의 경우, 상품 페이지에서 발급받은 쿠키로 리뷰 API를 호출해야 정상 응답을 받을 수 있습니다. 쿠키 없이 직접 API만 호출하면 "이 요청은 어디서 왔지?"라며 서버가 차단합니다.
쿠키의 종류와 역할
쿠팡 리뷰 크롤링에서 확인한 실제 쿠키들을 기준으로, 각 쿠키의 역할을 분류해 보겠습니다.
사용자 식별 쿠키
| 쿠키 이름 | 역할 | 특징 |
| PCID | PC 식별자 | 브라우저/기기 고유 식별 |
| MARKETID | 마켓 식별자 | 사용자 추적용 |
| member_srl | 회원 번호 | 로그인 시 발급 |
| sid | 세션 ID | 세션 관리 |
인증 관련 쿠키
| 쿠키 이름 | 역할 | 특징 |
| CT_AT | 인증 토큰 (JWT) | 가장 중요, API 호출 시 필수 |
| CSID | 세션 ID | 로그인 상태 유지 |
| CPUSR_RL | 사용자 역할/권한 | 접근 권한 확인 |
| ILOGIN | 로그인 여부 | Y/N 값 |
봇 탐지 관련 쿠키 (Akamai)
| 쿠키 이름 | 역할 | 특징 |
| _abck | Akamai 봇 관리자 쿠키 | 봇 여부 판단의 핵심 |
| bm_sz | 봇 관리자 세션 | 요청 패턴 분석 |
| bm_sv | 봇 관리자 검증 | 실시간 검증용 |
| bm_mi | 봇 관리자 정보 | 추가 검증 데이터 |
| ak_bmsc | Akamai 센서 데이터 | TLS 핑거프린트 등 포함 |
기타 쿠키
쿠키 이름 역할 특징
| 쿠키 이름 | 역할 | 특징 |
| x-coupang-target-market | 대상 시장 | KR(한국) |
| x-coupang-accept-language | 언어 설정 | ko-KR |
| gd1 | GDPR 동의 | Y/N |
크롤링 시 쿠키 관련 흔한 문제들
문제 1: 쿠키 누락
cURL이나 HTTP Request로 요청할 때 쿠키를 포함하지 않으면 서버는 새로운 방문자로 인식합니다. 특히 봇 탐지 쿠키(_abck 등)가 없으면 즉시 차단됩니다.
증상:
403 Forbidden
Access Denied
해결: 브라우저에서 복사한 전체 Cookie 헤더를 요청에 포함합니다.
문제 2: 쿠키 만료
쿠키는 영원히 유효하지 않습니다. Expires 또는 Max-Age 속성에 따라 일정 시간이 지나면 만료됩니다. 특히 인증 토큰(CT_AT)은 보안상 짧은 유효기간을 가집니다.
증상:
{
"error": "Unauthorized",
"message": "Token expired"
}
해결: 주기적으로 새로운 쿠키를 발급받아 갱신합니다.
문제 3: IP 불일치
일부 사이트는 쿠키 발급 시의 IP 주소를 기록하고, 이후 요청에서 IP가 다르면 쿠키를 무효화합니다. 쿠팡이 대표적인 예입니다.
증상:
- 브라우저에서는 성공
- 다른 머신의 n8n에서는 실패
해결: 쿠키를 발급받는 환경과 사용하는 환경의 IP가 동일해야 합니다.
문제 4: Secure 속성
Secure 속성이 설정된 쿠키는 HTTPS 요청에서만 전송됩니다. HTTP로 요청하면 쿠키가 누락됩니다.
증상:
- HTTPS URL에서는 성공
- HTTP URL에서는 실패
해결: 항상 HTTPS URL을 사용합니다.
개발자 도구에서 쿠키 확인하는 방법
브라우저의 개발자 도구를 활용하면 현재 페이지의 쿠키를 쉽게 확인할 수 있습니다. 이 방법을 알면 크롤링에 필요한 쿠키를 직접 파악할 수 있습니다.
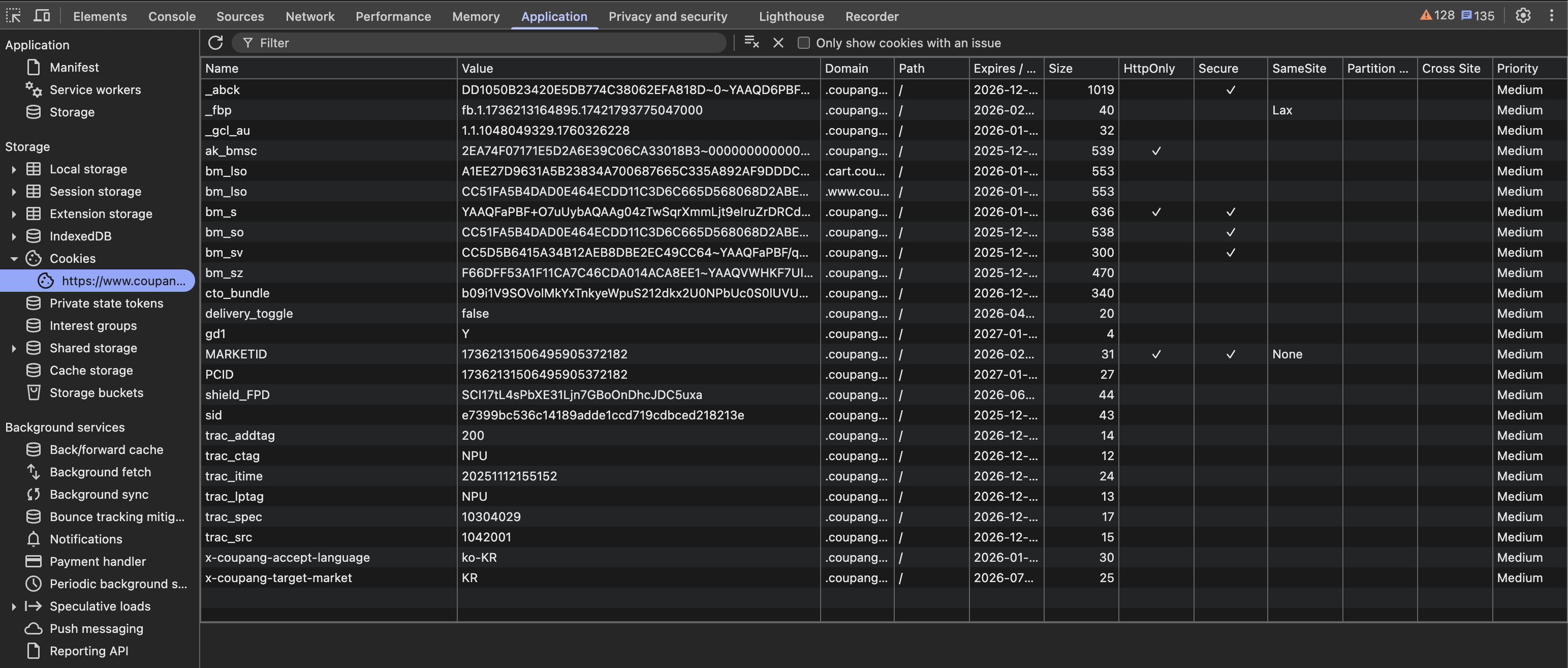
방법 1 | Application 탭에서 확인
- F12를 눌러 개발자 도구를 엽니다.
- Application 탭을 클릭합니다.
- 좌측 메뉴에서 Storage → Cookies를 펼칩니다.
- 해당 도메인을 클릭하면 모든 쿠키 목록이 표시됩니다.
이 방법의 장점은 각 쿠키의 Name, Value, Domain, Path, Expires, Size, HttpOnly, Secure, SameSite 속성을 모두 확인할 수 있다는 것입니다.
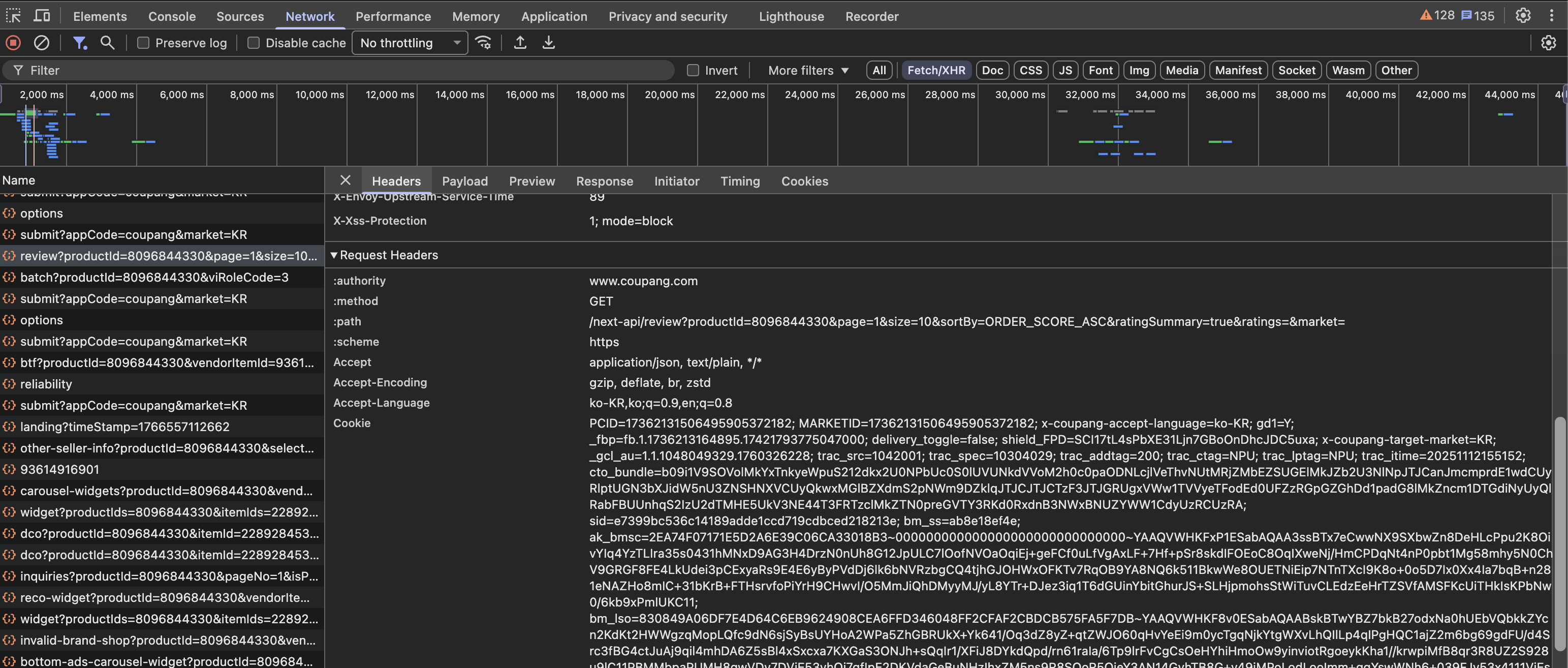
방법 2 | Network 탭에서 확인
- F12를 눌러 개발자 도구를 엽니다.
- Network 탭을 클릭합니다.
- 페이지를 새로고침하거나 원하는 동작을 수행합니다.
- 요청 목록에서 원하는 요청을 클릭합니다.
- Headers 탭에서 Request Headers → Cookie를 확인합니다.
이 방법의 장점은 실제로 서버에 전송된 쿠키를 확인할 수 있다는 것입니다. 또한 Copy as cURL을 통해 쿠키가 포함된 전체 요청을 복사할 수 있습니다.
방법 3: Console에서 확인
개발자 도구의 Console 탭에서 다음 명령어를 실행하면 현재 페이지의 쿠키를 확인할 수 있습니다.
document.cookie
단, HttpOnly 속성이 설정된 쿠키는 JavaScript로 접근할 수 없어 이 방법으로는 확인되지 않습니다.
크롤링에서 쿠키를 다루는 Best Practices
전체 Cookie 헤더 사용
개별 쿠키를 선별하기보다 브라우저에서 복사한 전체 Cookie 헤더를 그대로 사용하는 것이 안전합니다. 어떤 쿠키가 필수인지 정확히 알기 어렵고, 누락된 쿠키 하나 때문에 차단될 수 있기 때문입니다.
쿠키 유효성 검증 로직 추가
워크플로우에 응답을 검증하는 로직을 추가하여, 쿠키 만료 시 즉시 감지할 수 있도록 합니다.
// n8n Code 노드 예시
if (!$json.contents || $json.contents.length === 0) {
throw new Error('쿠키가 만료되었을 수 있습니다. 갱신이 필요합니다.');
}
쿠키 갱신 주기 파악
사이트마다 쿠키 유효기간이 다릅니다. 테스트를 통해 대략적인 만료 주기를 파악하고, 그 전에 갱신하는 습관을 들이면 좋습니다.
| 쿠키 유형 | 일반적인 유효기간 |
| 세션 쿠키 | 브라우저 종료 시까지 |
| 인증 토큰 | 몇 시간 ~ 1일 |
| 봇 탐지 쿠키 | 몇 분 ~ 몇 시간 |
| 영구 쿠키 | 몇 개월 ~ 몇 년 |
요청 간격 유지
짧은 시간에 너무 많은 요청을 보내면 서버가 쿠키를 무효화하거나 IP를 차단할 수 있습니다. n8n의 Wait 노드를 활용하여 요청 사이에 1~3초 간격을 두는 것이 좋습니다.
동일 환경 유지
쿠키를 발급받은 환경(IP, User-Agent, TLS 핑거프린트)과 사용하는 환경이 최대한 동일해야 합니다. 특히 IP가 다르면 많은 사이트에서 쿠키를 무효화합니다.
쿠키와 관련된 HTTP 헤더 정리
쿠키는 HTTP 헤더를 통해 주고받습니다. 크롤링 시 이 헤더들의 역할을 이해하면 문제 해결에 도움이 됩니다.
요청 헤더 (클라이언트 → 서버)
| 헤더 | 설명 | 예시 |
| Cookie | 저장된 쿠키 전송 | Cookie: PCID=123; _abck=abc... |
응답 헤더 (서버 → 클라이언트)
| 헤더 | 설명 | 예시 |
| Set-Cookie | 새 쿠키 발급/갱신 | Set-Cookie: token=xyz; Path=/; HttpOnly |
n8n HTTP Request에서 쿠키 설정
n8n HTTP Request 노드에서 쿠키를 직접 설정하려면 Header에 추가합니다.
| 설정 | 위치 | Name Value |
| Headers | Cookie | PCID=123; _abck=abc; CT_AT=eyJ... |
또는 Import cURL을 사용하면 -b 또는 --cookie 옵션에 포함된 쿠키가 자동으로 Header에 설정됩니다.
실전 팁: 쿠키 문제 디버깅
크롤링이 실패했을 때 쿠키 문제인지 확인하는 방법입니다.
체크리스트
- 쿠키가 요청에 포함되어 있나요?
- n8n 실행 결과에서 Request Headers를 확인합니다.
- 쿠키가 만료되지 않았나요?
- 브라우저 Application 탭에서 Expires 확인합니다.
- 필수 쿠키가 모두 있나요?
- 특히 _abck, CT_AT 등 핵심 쿠키를 확인합니다.
- IP가 동일한가요?
- 쿠키 발급 환경과 사용 환경의 IP를 비교합니다.
- HTTPS를 사용하고 있나요?
- Secure 쿠키는 HTTPS에서만 전송됩니다.
디버깅 순서
1. 브라우저에서 직접 요청 → 성공하면 쿠키/인증 문제 아님
2. 같은 머신의 터미널에서 cURL → 성공하면 n8n 설정 문제
3. n8n에서 Import cURL → 성공하면 기존 설정의 쿠키 문제
4. 여전히 실패 → IP 불일치 또는 추가 검증 로직 존재
요약
웹 크롤링에서 쿠키는 사용자 인증, 봇 탐지 우회, 세션 연속성 유지를 위한 핵심 요소입니다. 쿠키의 동작 원리와 속성을 이해하면 크롤링 실패 원인을 빠르게 파악하고 해결할 수 있습니다. 특히 쿠팡과 같이 강력한 봇 탐지를 사용하는 사이트에서는 올바른 쿠키 관리가 성공적인 크롤링의 핵심입니다.
| 핵심 포인트 | 설명 |
| 쿠키는 상태 유지의 핵심 | HTTP의 무상태 특성을 보완 |
| 봇 탐지 쿠키가 중요 | _abck, bm_sz 등 Akamai 쿠키 |
| 쿠키는 만료됨 | 주기적 갱신 필요 |
| IP 일치가 중요 | 발급 환경과 사용 환경 동일해야 함 |
| Import cURL이 편리 | 쿠키 포함 전체 요청을 한 번에 가져옴 |
4. n8n HTTP Request로 Browserless 호출하기
HTTP Request 노드 기본 설정
n8n에서 Browserless를 호출하기 위해서는 HTTP Request 노드를 사용합니다. Browserless의 각 API는 RESTful 방식으로 설계되어 있어, 적절한 URL과 요청 본문만 설정하면 손쉽게 연동할 수 있습니다. 여기서 중요한 점은 n8n과 Browserless가 동일한 Docker 네트워크에 있는지, 아니면 별도의 호스트에서 실행되는지에 따라 URL 설정 방식이 달라진다는 것입니다.
/content API로 HTML 가져오기
가장 기본적인 사용 방법은 /content API를 통해 JavaScript가 완전히 렌더링된 페이지의 HTML을 가져오는 것입니다. 이 방식은 단순히 페이지 소스를 확인하거나, 이후 n8n의 HTML Extract 노드로 데이터를 추출할 때 유용합니다.
HTTP Request 노드 설정:
| 설정 항목 | 값 |
| Method | POST |
| URL | http://browserless:3000/content (Docker 네트워크) 또는 http://localhost:3000/content |
| Body Content Type | JSON |
| Body | 아래 JSON 참조 |
{
"url": "https://www.coupang.com/vp/products/8096844330",
"waitForSelector": {
"selector": ".sdp-review__article__list",
"timeout": 30000
},
"gotoOptions": {
"waitUntil": "networkidle2",
"timeout": 60000
}
}/function API로 커스텀 스크립트 실행하기
더 복잡한 크롤링이 필요한 경우, /function API를 사용하여 Puppeteer 스크립트를 직접 실행할 수 있습니다. 이 방식은 로그인, 스크롤, 클릭 등의 사용자 상호작용을 시뮬레이션해야 하거나, 특정 API 요청을 가로채야 할 때 특히 유용합니다.
{
"code": "module.exports = async ({ page }) => \
{\n
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) \
AppleWebKit/537.36');\n await \
page.goto('https://www.coupang.com/vp/products/8096844330');\n \
await page.waitForSelector('.sdp-review__article__list');\n \
const reviews = await page.evaluate(() => \
{\n
return Array.from(document.querySelectorAll('.sdp-review__article__list__review')).map(el => \
({\n
rating: el.querySelector('.sdp-review__article__list__info__product-info__star-orange')?.style.width,\n \
content: el.querySelector('.sdp-review__article__list__review__content')?.textContent\n \
}));\n
});\n return reviews;\n
};"
}
# 위의 코드를 한 줄로 복사하세요.
# {
# "code": "module.exports = async ({ page }) => {\n await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36');\n await page.goto('https://www.coupang.com/vp/products/8096844330');\n await page.waitForSelector('.sdp-review__article__list');\n const reviews = await page.evaluate(() => {\n return Array.from(document.querySelectorAll('.sdp-review__article__list__review')).map(el => ({\n rating: el.querySelector('.sdp-review__article__list__info__product-info__star-orange')?.style.width,\n content: el.querySelector('.sdp-review__article__list__review__content')?.textContent\n }));\n });\n return reviews;\n};"
# }5. 방법 1 | Browserless /function API로 리뷰 API 직접 호출
쿠팡 리뷰 API 분석하기 (예시)
오늘 우리는 쿠팡사이트에서 특정 제품의 리뷰와 관련된 글들을 크롤링하려고 합니다. 특정 리뷰API를 크롤링하기 위해서는 개발자모드(F12) > Network > Fetch/XHR > 'review?productID=xxxxxxxx&page...'를 선택하신 다음 마우스 우클릭 > Copy > Copy as cURL을 선택하시면 cURL을 복사할 수 있습니다.
복사한 cURL을 분석하면, 쿠팡은 리뷰 데이터를 별도의 API 엔드포인트(/next-api/review)를 통해 JSON 형식으로 제공하고 있음을 알 수 있습니다. 이 API에 직접 접근할 수 있다면 HTML 파싱 없이 구조화된 데이터를 바로 얻을 수 있어 훨씬 효율적입니다. 다만 쿠팡의 봇 탐지 시스템이 쿠키와 헤더를 철저히 검증하기 때문에, 적절한 세션 정보 없이는 접근이 차단됩니다.
쿠팡 리뷰 API 엔드포인트 구조:
https://www.coupang.com/next-api/review
?productId=8096844330 # 상품 ID
&page=1 # 페이지 번호
&size=10 # 한 페이지당 리뷰 수
&sortBy=ORDER_SCORE_ASC # 정렬 기준
&ratingSummary=true # 평점 요약 포함 여부
Browserless의 /function API를 활용하면 실제 브라우저 세션 내에서 리뷰 API를 호출할 수 있습니다. 이 방식의 핵심은 먼저 상품 페이지에 접속하여 유효한 쿠키와 세션을 획득한 후, 해당 세션으로 리뷰 API에 요청을 보내는 것입니다. 브라우저 컨텍스트 내에서 fetch를 실행하기 때문에 쿠키가 자동으로 포함되어 인증 문제를 우회할 수 있습니다.
n8n HTTP Request 노드 설정:
| 설정 항목 | 값 |
| Method | POST |
| URL | http://browserless:3000/function |
| Body Content Type | JSON |
요청 본문 (Body):
{
"code": "module.exports = async ({ page }) => {\n // 1. 실제 브라우저처럼 User-Agent 설정\n await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36');\n \n // 2. 추가 헤더 설정\n await page.setExtraHTTPHeaders({\n 'accept-language': 'ko-KR,ko;q=0.9,en;q=0.8',\n 'sec-ch-ua': '\"Chromium\";v=\"140\", \"Google Chrome\";v=\"140\"',\n 'sec-ch-ua-mobile': '?0',\n 'sec-ch-ua-platform': '\"macOS\"'\n });\n \n // 3. 상품 페이지 방문하여 쿠키 획득\n const productUrl = 'https://www.coupang.com/vp/products/8096844330';\n await page.goto(productUrl, { waitUntil: 'networkidle2', timeout: 60000 });\n \n // 4. 페이지 로딩 대기\n await page.waitForTimeout(3000);\n \n // 5. 브라우저 컨텍스트에서 리뷰 API 호출\n const reviewData = await page.evaluate(async () => {\n const response = await fetch('https://www.coupang.com/next-api/review?productId=8096844330&page=1&size=10&sortBy=ORDER_SCORE_ASC&ratingSummary=true', {\n method: 'GET',\n headers: {\n 'accept': 'application/json',\n 'referer': window.location.href\n },\n credentials: 'include'\n });\n return response.json();\n });\n \n return reviewData;\n};"
}
# 내부 코드 풀어 보기
{
"code": "module.exports = async ({ page }) => \
{
// 1. 실제 브라우저처럼 User-Agent 설정
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/140.0.0.0 Safari/537.36');
// 2. 추가 헤더 설정
await page.setExtraHTTPHeaders(
{
'accept-language': 'ko-KR,ko;q=0.9,en;q=0.8',
'sec-ch-ua': '\"Chromium\";v=\"140\", \"Google Chrome\";v=\"140\"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '\"macOS\"'
});
// 3. 상품 페이지 방문하여 쿠키 획득
const productUrl = 'https://www.coupang.com/vp/products/8096844330';
await page.goto(productUrl,
{
waitUntil: 'networkidle2',
timeout: 60000
});
// 4. 페이지 로딩 대기
await page.waitForTimeout(3000);
// 5. 브라우저 컨텍스트에서 리뷰 API 호출
const reviewData = await page.evaluate(async () => {
const response = await fetch('https://www.coupang.com/next-api/review?\
productId=8096844330&page=1&size=10&sortBy=ORDER_SCORE_ASC&ratingSummary=true',
{
method: 'GET',
headers: {
'accept': 'application/json',
'referer': window.location.href
},
credentials: 'include'
});
return response.json();
});
return reviewData;\n};"
}6. 방법 2 | 페이지 렌더링 후 DOM에서 리뷰 추출
API 직접 호출이 차단되는 경우, 대안으로 페이지를 완전히 렌더링한 후 DOM에서 리뷰 데이터를 추출하는 방법이 있습니다. 이 방식은 사용자가 실제로 페이지를 보는 것과 동일한 데이터를 수집하므로, 봇 탐지를 우회할 확률이 더 높습니다. 다만 페이지 렌더링에 시간이 더 소요되고, 추출할 CSS 선택자를 정확히 파악해야 합니다.
{
"code": "module.exports = async ({ page }) => {\n await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36');\n \n await page.goto('https://www.coupang.com/vp/products/8096844330', {\n waitUntil: 'networkidle2',\n timeout: 60000\n });\n \n // 리뷰 섹션이 로드될 때까지 대기\n await page.waitForSelector('.sdp-review__article__list', { timeout: 30000 }).catch(() => null);\n \n // 리뷰 탭 클릭 (필요한 경우)\n const reviewTab = await page.$('.sdp-review__article__list__review__count');\n if (reviewTab) await reviewTab.click();\n \n await page.waitForTimeout(2000);\n \n // DOM에서 리뷰 데이터 추출\n const reviews = await page.evaluate(() => {\n const reviewElements = document.querySelectorAll('.sdp-review__article__list__review');\n return Array.from(reviewElements).map(el => {\n const starEl = el.querySelector('.sdp-review__article__list__info__product-info__star-orange');\n const rating = starEl ? parseInt(starEl.style.width) / 20 : null;\n const content = el.querySelector('.sdp-review__article__list__review__content')?.textContent?.trim() || '';\n const date = el.querySelector('.sdp-review__article__list__info__product-info__reg-date')?.textContent?.trim() || '';\n const userName = el.querySelector('.sdp-review__article__list__info__user__name')?.textContent?.trim() || '';\n \n return { rating, content, date, userName };\n });\n });\n \n return { success: true, count: reviews.length, reviews };\n};"
}
# 코드 분해해서 상세히 보기
{
"code": "module.exports = async ({ page }) => {
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36');
await page.goto('https://www.coupang.com/vp/products/8096844330', {
waitUntil: 'networkidle2',
timeout: 60000
});
// 리뷰 섹션이 로드될 때까지 대기
await page.waitForSelector('.sdp-review__article__list', \
{ timeout: 30000 }).catch(() => null);
// 리뷰 탭 클릭 (필요한 경우)
const reviewTab = await page.$('.sdp-review__article__list__review__count');
if (reviewTab) await reviewTab.click();
await page.waitForTimeout(2000);
// DOM에서 리뷰 데이터 추출
const reviews = await page.evaluate(() => {
const reviewElements = document.querySelectorAll('.sdp-review__article__list__review');
return Array.from(reviewElements).map(el => {
const starEl = el.querySelector('.sdp-review__article__list__info__product-info__star-orange');
const rating = starEl ? parseInt(starEl.style.width) / 20 : null;
const content = el.querySelector('.sdp-review__article__list__review__content')?.textContent?.trim() || '';
const date = el.querySelector('.sdp-review__article__list__info__product-info__reg-date')?.textContent?.trim() || '';
const userName = el.querySelector('.sdp-review__article__list__info__user__name')?.textContent?.trim() || '';
return { rating, content, date, userName };
});
});
return { success: true, count: reviews.length, reviews };
};"
}7. 방법 3 | 단순 버전 vs 스텔스 버전 선택 가이드 (권장)
웹사이트마다 봇 탐지 수준이 다르기 때문에, 상황에 맞는 방법을 선택하는 것이 중요합니다. 불필요하게 복잡한 설정을 할 필요도 없고, 반대로 단순한 방법으로 차단당할 필요도 없습니다. 아래 표를 참고하여 크롤링 대상 사이트에 맞는 방법을 선택해 주세요.
| 사이트 유형 | 예시 | 권장 방법 |
| 일반 사이트 (봇 탐지 없음) | 개인 블로그, 소규모 쇼핑몰, 공공 데이터 | 방법 3-A: /content API 단순 버전 |
| 봇 탐지 사이트 (Akamai, Cloudflare) | 쿠팡, 네이버, 11번가, 대형 포털 | 방법 3-B: /function API + 스텔스 모드 |
방법 3-A : 일반 사이트용 단순 버전
봇 탐지가 없는 일반 사이트라면 /content API만으로 충분합니다. 설정이 매우 간단하고, 별도의 Puppeteer 코드 작성이 필요 없습니다. JavaScript로 렌더링되는 동적 콘텐츠도 문제없이 가져올 수 있습니다.
HTTP Request 노드 설정:
| 설정 | 항목값 |
| Method | POST |
| URL | http://browserless:3000/content |
| Body Content Type | JSON |
Request Body:
{
"url": "https://example.com/products/12345",
"waitFor": 3000,
"gotoOptions": {
"waitUntil": "networkidle0"
}
}
이게 전부입니다. url에 크롤링할 주소를 넣고, waitFor로 JavaScript 렌더링 대기 시간(밀리초)을 지정하면 됩니다. networkidle0은 네트워크 요청이 완전히 멈출 때까지 기다리라는 의미로, 동적 콘텐츠가 모두 로딩된 후의 HTML을 받을 수 있습니다. 응답으로 전체 HTML이 텍스트로 반환되며, 이후 HTML 노드로 파싱하면 됩니다.
워크플로우 구조:
[HTTP Request] → [HTML Extract] → [Code] → [저장]
↓ ↓
/content API CSS 선택자로
(HTML 반환) 데이터 추출방법 3-B: 봇 탐지 사이트용 스텔스 버전 (쿠팡 등)
쿠팡, 네이버, 11번가 등 대형 사이트는 Akamai, Cloudflare 같은 봇 탐지 시스템을 사용합니다. 이런 사이트에 방법 3-A로 접근하면 Access Denied 오류가 발생합니다. 반드시 /function API와 스텔스 모드를 함께 사용해야 합니다.
사전 준비: Browserless 스텔스 모드 활성화
먼저 Docker Compose 파일에서 스텔스 모드 환경변수를 추가해야 합니다. 스텔스 모드가 활성화되면 Browserless가 navigator.webdriver 속성을 숨기고, Chrome 플러그인과 언어 설정을 실제 브라우저처럼 위장하며, headless 브라우저 탐지를 자동으로 우회합니다.
# docker-compose.yml
version: '3.8'
services:
browserless:
image: browserless/chrome:latest
container_name: browserless
environment:
- ENABLE_STEALTH=true # 스텔스 모드 활성화
- DEFAULT_STEALTH=true # 모든 요청에 스텔스 적용
- CONNECTION_TIMEOUT=120000 # 연결 타임아웃 2분
- MAX_CONCURRENT_SESSIONS=10 # 동시 세션 수
ports:
- "3000:3000"
networks:
- automation-network
환경변수 변경 후에는 컨테이너를 재시작해서 변경내용을 적요합니다.
docker-compose down && docker-compose up -dHTTP Request 노드 설정:
| 설정 | 항목값 |
| Method | POST |
| URL | http://browserless:3000/function |
| Body Content Type | JSON |
Request Body (한 줄 버전 - 복사용):
{
"code": "module.exports = async ({ page }) => { await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36'); await page.setExtraHTTPHeaders({ 'accept-language': 'ko-KR,ko;q=0.9', 'sec-ch-ua': '\"Chromium\";v=\"140\"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '\"macOS\"' }); await page.goto('https://www.coupang.com/vp/products/8096844330', { waitUntil: 'networkidle2', timeout: 60000 }); await page.waitForTimeout(3000); return await page.content(); }"
}팁: 위 코드를 보기 쉽게 정리하면 다음과 같습니다:
module.exports = async ({ page }) => {
// 1. User-Agent 설정
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36');
// 2. 필수 헤더 설정 (Akamai 봇 탐지 우회)
await page.setExtraHTTPHeaders({
'accept-language': 'ko-KR,ko;q=0.9',
'sec-ch-ua': '"Chromium";v="140"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"'
});
// 3. 페이지 접속 및 로딩 대기
await page.goto('https://www.coupang.com/vp/products/8096844330', {
waitUntil: 'networkidle2',
timeout: 60000
});
// 4. 추가 대기 (동적 콘텐츠 로딩)
await page.waitForTimeout(3000);
// 5. HTML 반환
return await page.content();
};왜 /content API를 못 쓰나요? : /content API는 setExtraHTTPHeaders 옵션을 지원하지 않습니다. 쿠팡의 Akamai 봇 탐지는 sec-ch-ua, sec-ch-ua-platform 같은 Client Hints 헤더를 검사하는데, 이 헤더들을 설정하려면 반드시 /function API를 사용해야 합니다.
워크플로우 구조:
[HTTP Request] → [HTML Extract] → [Code] → [저장]
↓ ↓
/function API CSS 선택자로
(HTML 반환) 데이터 추출Step 2: HTML 노드로 데이터 추출 (공통)
방법 3-A와 3-B 모두 HTTP Request 노드 다음에 n8n의 HTML 노드를 연결합니다. 두 방법 모두 HTML을 문자열로 반환하므로, 이를 파싱하여 원하는 데이터를 추출합니다. CSS 선택자를 사용해 HTML에서 원하는 요소들의 텍스트나 속성값을 배열로 반환받을 수 있습니다.
HTML 노드 설정:
| 설정 | 항목값 |
| Operation | Extract HTML Content |
| Source Data | JSON |
| JSON Property | 응답 필드명 확인 후 설정 (예: data 또는 빈 값) |
Extraction Values 설정:
| Key | CSS Selector | Return Value |
| reviewContent | .sdp-review__article__list__review__content | Text |
| rating | .sdp-review__article__list__info__product-info__star-orange | Attribute: style |
| userName | .sdp-review__article__list__info__user__name | Text |
| date | .sdp-review__article__list__info__product-info__reg-date | Text |
Step 3: Code 노드로 데이터 정제 (선택사항)
HTML 노드에서 추출한 데이터가 배열 형태로 나오므로, 필요에 따라 Code 노드에서 구조를 정리할 수 있습니다. 예를 들어 별점의 style 속성값(width: 80%)에서 숫자만 추출하거나, 여러 배열을 하나의 객체 배열로 합치는 작업을 수행합니다.
// HTML 노드 출력 예시: { reviewContent: [...], rating: [...], userName: [...], date: [...] }
const data = $input.first().json;
const reviews = [];
const count = data.reviewContent?.length || 0;
for (let i = 0; i < count; i++) {
// style="width: 80%" 에서 숫자 추출 후 5점 만점으로 변환
const styleValue = data.rating?.[i] || '';
const widthMatch = styleValue.match(/width:\s*(\d+)%/);
const rating = widthMatch ? parseInt(widthMatch[1]) / 20 : null;
reviews.push({
json: {
rating: rating,
content: data.reviewContent?.[i]?.trim() || '',
userName: data.userName?.[i]?.trim() || '',
date: data.date?.[i]?.trim() || '',
crawledAt: new Date().toISOString()
}
});
}
return reviews;방법 3의 워크플로우 구조:
[Schedule Trigger] → [HTTP Request] → [HTML Extract] → [Code] → [Google Sheets]
↓ ↓ ↓
Browserless CSS 선택자로 데이터 정제
/function API 텍스트 추출 (선택사항)
(HTML 반환)방법 3의 장점:
방법 3은 상황에 맞는 최적의 선택을 할 수 있다는 점에서 가장 실용적입니다. 일반 사이트에는 단순한 3-A 버전으로 빠르게 구현하고, 봇 탐지가 있는 사이트에만 3-B 버전을 사용하면 됩니다. 두 버전 모두 HTML 추출 로직을 Puppeteer 스크립트에 넣지 않고 n8n의 HTML 노드에서 처리하므로 유지보수가 쉽습니다. CSS 선택자만 수정하면 되므로 웹사이트 구조가 변경되어도 코드를 거의 건드릴 필요가 없습니다.
8. 방법 4 | /function API로 커스텀 스크립트 실행
왜 /function API가 필요한가요?
앞서 살펴본 /content API는 단순히 페이지의 HTML을 가져오는 데 적합하지만, 복잡한 상호작용이 필요한 경우에는 한계가 있습니다. 로그인이 필요하거나, 특정 버튼을 클릭해야 하거나, 스크롤을 내려야 콘텐츠가 로딩되는 사이트에서는 /function API를 사용해야 합니다. /function API는 Puppeteer 스크립트를 직접 실행할 수 있어서, 마치 사람이 브라우저를 조작하는 것처럼 다양한 동작을 자동화할 수 있습니다.
Browserless v1 vs v2 문법 차이
Browserless를 사용할 때 가장 중요한 것은 버전에 따른 문법 차이를 이해하는 것입니다. v1과 v2는 코드 작성 방식이 완전히 다르기 때문에, 자신이 설치한 버전에 맞는 문법을 사용해야 합니다. 잘못된 문법을 사용하면 "module is not defined" 또는 "export is not defined"와 같은 에러가 발생합니다.
| 구분 | Browserless V1 | Browserless V2 |
| Docker 이미지 | browserless/chrome:latest | ghcr.io/browserless/chromium:latest |
| 함수 선언 | module.exports = async ({ page }) => { } | export default async ({ page }) => { } |
| Stealth 모드 | 환경변수 ENABLE_STEALTH=true | 수동 설정 필요 |
| 기반 엔진 | Puppeteer | Puppeteer (Chromium) |
Docker Compose 설정
n8n과 Browserless를 함께 운영하기 위한 Docker Compose 설정입니다. 두 컨테이너가 같은 네트워크에 있어야 서로 통신할 수 있으므로, networks 설정에 주의해야 합니다.
# docker-compose.yml
version: '3.8'
services:
browserless:
image: ghcr.io/browserless/chromium:latest # v2 버전
container_name: browserless
environment:
- TIMEOUT=120000 # 타임아웃 2분
- CONCURRENT=10 # 동시 세션 수
- HEALTH=true # 헬스체크 활성화
ports:
- "3000:3000"
restart: unless-stopped
networks:
- n8n-network
n8n:
image: n8nio/n8n:latest
container_name: n8n
# ... 기타 n8n 설정 ...
networks:
- n8n-network
networks:
n8n-network:
driver: bridge실전 예제: 네이버 블로그 크롤링
네이버 블로그는 JavaScript로 콘텐츠를 렌더링하기 때문에 단순 HTTP Request로는 본문을 가져올 수 없습니다. Browserless의 /function API를 사용하면 실제 브라우저처럼 페이지를 완전히 로딩한 후 콘텐츠를 추출할 수 있습니다. 아래 예제에서는 네이버 블로그 포스트의 제목과 본문을 가져오는 방법을 보여드립니다.
n8n HTTP Request 노드 설정
| 설정 항목 | 값 |
| Method | POST |
| URL | http://browserless:3000/function |
| Body Content Type | JSON |
Request Body (v2 문법)
{
"code": "export default async ({ page }) => { await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36'); await page.setExtraHTTPHeaders({ 'accept-language': 'ko-KR,ko;q=0.9' }); await page.goto('https://blog.naver.com/PostView.naver?blogId=example&logNo=123456789', { waitUntil: 'networkidle2', timeout: 60000 }); await new Promise(r => setTimeout(r, 3000)); const data = await page.evaluate(() => { const title = document.querySelector('.se-title-text')?.innerText || ''; const content = document.querySelector('.se-main-container')?.innerText || ''; return { title, content }; }); return data; }"
}코드 설명 (가독성 좋은 버전)
위의 한 줄 코드를 보기 쉽게 정리하면 다음과 같습니다. 실제 n8n에서 사용할 때는 한 줄로 작성해야 하지만, 각 단계가 어떤 역할을 하는지 이해하는 것이 중요합니다.
export default async ({ page }) => {
// 1. User-Agent 설정 (실제 브라우저처럼 위장)
await page.setUserAgent(
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36'
);
// 2. 한국어 헤더 설정
await page.setExtraHTTPHeaders({
'accept-language': 'ko-KR,ko;q=0.9'
});
// 3. 페이지 접속 (네트워크 요청이 멈출 때까지 대기)
await page.goto('https://blog.naver.com/PostView.naver?blogId=example&logNo=123456789', {
waitUntil: 'networkidle2',
timeout: 60000
});
// 4. 추가 대기 (동적 콘텐츠 로딩 시간 확보)
await new Promise(r => setTimeout(r, 3000));
// 5. DOM에서 데이터 추출
const data = await page.evaluate(() => {
const title = document.querySelector('.se-title-text')?.innerText || '';
const content = document.querySelector('.se-main-container')?.innerText || '';
return { title, content };
});
return data;
};주요 Puppeteer 메서드 정리
/function API에서 사용할 수 있는 주요 Puppeteer 메서드들입니다. 이 메서드들을 조합하면 대부분의 웹 크롤링 시나리오를 처리할 수 있습니다.
| 메서드 | 설명 | 사용 예시 |
| page.goto(url, options) | 페이지 이동 | await page.goto('https://example.com', { waitUntil: 'networkidle2' }) |
| page.setUserAgent(ua) | User-Agent 설정 | await page.setUserAgent('Mozilla/5.0...') |
| page.setExtraHTTPHeaders(headers) | HTTP 헤더 추가 | await page.setExtraHTTPHeaders({ 'accept-language': 'ko-KR' }) |
| page.evaluate(fn) | 브라우저 컨텍스트에서 JS 실행 | await page.evaluate(() => document.title) |
| page.content() | 전체 HTML 반환 | return await page.content() |
| page.cookies() | 현재 쿠키 목록 반환 | const cookies = await page.cookies() |
| page.click(selector) | 요소 클릭 | await page.click('.submit-button') |
| page.type(selector, text) | 텍스트 입력 | await page.type('#search-input', '검색어') |
| page.waitForSelector(selector) | 요소가 나타날 때까지 대기 | await page.waitForSelector('.loaded-content') |
/function API의 한계
Browserless /function API는 강력하지만 모든 상황에서 완벽하지는 않습니다. 특히 쿠팡과 같이 Akamai Bot Manager를 사용하는 사이트에서는 다음과 같은 문제가 발생할 수 있습니다.
- 첫째, 페이지 접속은 성공하지만 내부 API 호출이 차단될 수 있습니다. Browserless로 쿠팡 상품 페이지에 접속하면 HTML은 정상적으로 가져올 수 있지만, 그 세션에서 리뷰 API(/next-api/review)를 호출하면 403 Access Denied가 발생합니다. 이는 Akamai가 쿠키 발급 시점의 다양한 정보(IP, TLS 핑거프린트, 행동 패턴 등)를 기록하고, API 호출 시 이를 검증하기 때문입니다.
- 둘째, 반복 요청 시 IP 차단이 발생할 수 있습니다. 짧은 시간에 여러 번 요청을 보내면 봇으로 인식되어 일시적 또는 영구적으로 차단될 수 있습니다. 이 경우 컨테이너를 재시작하거나 일정 시간 대기해야 합니다.
이러한 한계 때문에 쿠팡과 같은 사이트에서는 다음 섹션에서 설명하는 방법 5 : HTTP Request + Import cURL 방식이 더 효과적일 수 있습니다.
9. 방법 5 | HTTP Request + Import cURL (실전 권장)
왜 이 방법이 필요한가요?
앞서 Browserless의 한계를 설명드렸습니다. 쿠팡처럼 강력한 봇 탐지 시스템을 갖춘 사이트에서는 헤드리스 브라우저로도 내부 API를 호출하기 어렵습니다. 하지만 재미있는 사실이 있습니다. 브라우저 개발자 도구에서 복사한 cURL 명령어를 n8n HTTP Request에 그대로 Import하면 동작한다는 것입니다.
이 방법이 작동하는 이유는 브라우저에서 직접 복사한 cURL에는 실제 세션에서 발급받은 쿠키, 토큰, 헤더가 모두 포함되어 있기 때문입니다. n8n은 이 정보를 그대로 사용하여 마치 해당 브라우저 세션에서 요청을 보내는 것처럼 동작합니다.
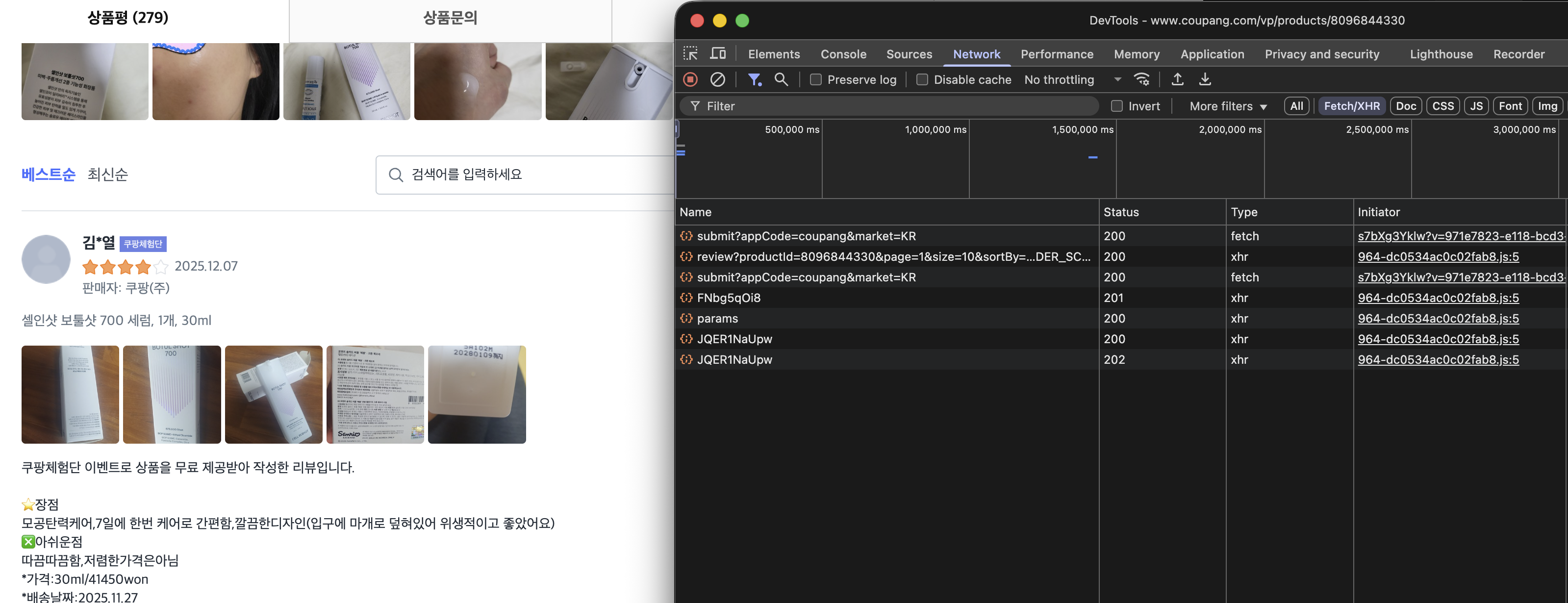
cURL 복사 방법
브라우저 개발자 도구에서 API 요청의 cURL을 복사하는 방법은 다음과 같습니다. Chrome, Edge, Whale 등 Chromium 기반 브라우저에서 동일하게 작동합니다.
- 브라우저에서 대상 페이지 열기: 쿠팡 상품 페이지(https://www.coupang.com/vp/products/상품ID)에 접속합니다.
- 개발자 도구 열기: F12 키를 누르거나 마우스 우클릭 후 "검사"를 선택합니다.
- Network 탭으로 이동: 상단 탭에서 "Network"를 클릭합니다.
- Fetch/XHR 필터 적용: Network 탭 내 필터 버튼 중 "Fetch/XHR"을 클릭하여 API 요청만 표시합니다.
- 리뷰 API 찾기: 페이지에서 리뷰 섹션으로 스크롤하면 review가 포함된 요청이 나타납니다. /next-api/review?productId=... 형태의 요청을 찾습니다.
- cURL로 복사: 해당 요청을 우클릭하고 "Copy" → "Copy as cURL"을 선택합니다.
n8n HTTP Request에서 Import cURL 사용하기
복사한 cURL을 n8n에서 사용하는 방법은 매우 간단합니다. HTTP Request 노드의 "Import cURL" 기능을 사용하면 URL, 헤더, 쿠키, 파라미터가 자동으로 채워집니다.
설정 단계
- HTTP Request 노드 추가: 워크플로우에 HTTP Request 노드를 추가합니다.
- Import cURL 클릭: 노드 설정 화면 우측 상단의 "Import cURL" 버튼을 클릭합니다.
- cURL 붙여넣기: 복사해둔 cURL 명령어를 붙여넣고 "Import"를 클릭합니다.
- 자동 채워진 필드 확인: Method(GET), URL, Query Parameters, Headers가 자동으로 설정됩니다.
Import 후 자동 설정되는 필드
| 필드 | 예시 값 |
| Method | GET |
| URL | https://www.coupang.com/next-api/review |
| Query Parameters | productId=8096844330, page=1, size=10, sortBy=ORDER_SCORE_ASC, ratingSummary=true |
| Headers | accept, accept-language, sec-ch-ua, sec-fetch-dest, user-agent 등 |
| Cookies | PCID, MARKETID, _abck, bm_sv, CT_AT 등 (Header로 포함) |
응답 데이터 구조
Import cURL로 요청을 실행하면 쿠팡 리뷰 API는 다음과 같은 JSON 구조로 응답합니다. 이 데이터를 n8n의 후속 노드에서 가공하여 원하는 형태로 활용할 수 있습니다.
{
"isPrev": false,
"isNext": true,
"isPaging": true,
"pageList": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"contents": [
{
"reviewId": 812007608,
"productId": 8096844330,
"vendorItemId": 93614916901,
"itemId": 22892845330,
"rating": 4,
"commentCount": 0,
"helpfulCount": 0,
"itemName": "셀인샷 보툴샷 700 세럼, 1개, 30ml",
"content": "실제 리뷰 내용이 여기에 표시됩니다...",
"reviewAt": 1765118831000,
"member": {
"type": "USER",
"id": 143004918,
"name": "김*엘",
"email": "sdk****@naver.com",
"displayWriter": "쿠팡실구매자"
}
}
// ... 추가 리뷰들
]
}
문제점 1 | 쿠키 만료와 수동 갱신
이 방법의 가장 큰 문제점은 쿠키가 만료되면 더 이상 작동하지 않는다는 것입니다. 쿠팡의 세션 쿠키는 일정 시간이 지나면 만료되며, 만료된 쿠키로 요청하면 403 Access Denied 또는 로그인 페이지로 리다이렉트됩니다.
쿠키 만료 시 증상
| 증상 | 설명 |
| 403 Access Denied | 세션이 완전히 만료됨 |
| 빈 응답 또는 에러 JSON | 인증 토큰 만료 |
| 로그인 페이지 HTML 반환 | 세션 쿠키 무효화 |
해결 방안: Schedule 노드를 활용한 주기적 쿠키 갱신
완전 자동화는 어렵지만, Schedule 노드를 활용하여 쿠키 갱신이 필요한 시점을 알림받고, 수동으로 갱신하는 반자동 워크플로우를 구성할 수 있습니다.
[Schedule Trigger] → [HTTP Request: 리뷰 API 호출] → [IF: 응답 정상?]
↓ Yes ↓ No
[데이터 처리] [Slack/Email 알림: 쿠키 갱신 필요]워크플로우 구성
1. Schedule Trigger 노드
| 설정 | 값 |
| Trigger Interval | Hours |
| Hours Between Triggers | 1 (또는 원하는 주기) |
2. HTTP Request 노드 (Import cURL로 설정)
3. IF 노드 - 응답 검증
| 설정 | 값 |
| Condition | {{ $json.contents }} is not empty |
4. Slack/Email 노드 - 실패 시 알림
쿠키가 만료되어 응답이 비정상일 때 담당자에게 알림을 보내 cURL을 다시 복사하도록 안내합니다.
문제점 2 | 페이지네이션 처리
쿠팡 리뷰 API는 한 번에 최대 10개의 리뷰만 반환합니다. 전체 리뷰를 수집하려면 Loop 노드를 사용하여 페이지를 순회해야 합니다.
페이지네이션 응답 필드
| 필드 | 설명 |
| isPrev | 이전 페이지 존재 여부 |
| isNext | 다음 페이지 존재 여부 (핵심!) |
| isPaging | 페이지네이션 활성화 여부 |
| pageList | 사용 가능한 페이지 번호 배열 |
Loop를 활용한 전체 리뷰 수집 워크플로우
[Manual/Schedule Trigger] → [Set: page=1, allReviews=[]] → [Loop]
↓
┌─────────────────────────────────┘
↓
[HTTP Request: 리뷰 API (page 파라미터 동적)]
↓
[Code: allReviews에 추가]
↓
[IF: isNext === true?]
↓ Yes ↓ No
[Set: page = page + 1] [Loop 종료]
↓
[Loop 처음으로]
[Loop 종료 후] → [전체 리뷰 데이터 처리]상세 노드 설정
1. Set 노드 (초기화)
{
"page": 1,
"allReviews": []
}
2. HTTP Request 노드 (Loop 내부)
URL의 page 파라미터를 동적으로 설정합니다.
| 설정 | 값 |
| URL | https://www.coupang.com/next-api/review |
| Query Parameters - page | {{ $json.page }} |
| Query Parameters - size | 10 |
| Query Parameters - productId | 8096844330 |
| Query Parameters - sortBy | ORDER_SCORE_ASC |
| Query Parameters - ratingSummary | true |
3. Code 노드 (리뷰 누적)
// 현재까지 수집된 리뷰와 새로 가져온 리뷰를 합침
const currentReviews = $('Set').first().json.allReviews || [];
const newReviews = $input.first().json.contents || [];
return {
page: $('Set').first().json.page,
allReviews: [...currentReviews, ...newReviews],
isNext: $input.first().json.isNext,
totalCollected: currentReviews.length + newReviews.length
};
4. IF 노드 (계속 여부 판단)
| 설정 | 값 |
| Condition | {{ $json.isNext }} equals true |
5. Set 노드 (페이지 증가, Yes 브랜치)
{
"page": "{{ $json.page + 1 }}",
"allReviews": "{{ $json.allReviews }}"
}주의사항: 요청 간격 조절
반복 요청 시 서버에 부담을 주지 않도록 Wait 노드를 추가하여 요청 간격을 조절하는 것이 좋습니다. 1~3초 정도의 간격을 두면 차단 위험을 줄일 수 있습니다.
[HTTP Request] → [Wait: 2초] → [Code] → [IF] → ...완성된 워크플로우 구조
모든 요소를 종합한 완성된 워크플로우는 다음과 같습니다. 이 구조는 쿠키 만료 감지, 페이지네이션, 데이터 저장을 모두 포함합니다.
[Schedule Trigger: 매일 오전 9시]
↓
[Set: 초기화 (page=1, allReviews=[])]
↓
[Loop Over Items]
↓
┌────┴────┐
↓ ↓
[HTTP Request: 리뷰 API]
↓
[IF: 응답에 contents 존재?]
↓ Yes ↓ No
[Code: 리뷰 누적] [Slack: 쿠키 갱신 필요 알림]
↓ ↓
[Wait: 2초] [Stop and Error]
↓
[IF: isNext === true?]
↓ Yes ↓ No
[Set: page++] [Loop 종료]
↓
[Loop 처음으로]
[Loop 종료 후]
↓
[Google Sheets/Airtable: 데이터 저장]
↓
[Slack: 수집 완료 알림 (총 N개 리뷰)]이 방법의 장단점 정리
| 장점 | 단점 |
| 실제로 동작함 (검증됨) | 쿠키 수동 갱신 필요 |
| 설정이 간단함 (Import cURL) | 브라우저 접근 필요 |
| JSON 응답으로 파싱 쉬움 | 쿠키 만료 시점 예측 어려움 |
| 전체 리뷰 수집 가능 (Loop) | 완전 자동화 불가 |
| 추가 인프라 불필요 | IP 차단 위험 (과도한 요청 시) |
현실적인 운영 방안
완전 자동화가 어렵다면, 다음과 같은 반자동 운영 방안을 고려해 볼 수 있습니다.
- 주 1회 수동 쿠키 갱신: 매주 월요일 아침에 브라우저에서 cURL을 복사하여 n8n 워크플로우를 업데이트합니다. 이 작업은 1~2분이면 충분합니다.
- 쿠키 만료 알림 설정: 워크플로우에 응답 검증 로직을 추가하여, 쿠키가 만료되면 즉시 Slack이나 이메일로 알림을 받습니다.
- 일일 1회 실행: 리뷰 수집 주기를 일일 1회로 설정하면 쿠키 만료 전에 충분한 데이터를 수집할 수 있습니다.
- 데이터 중복 제거: reviewId를 기준으로 중복을 제거하여 깔끔한 데이터셋을 유지합니다.
방법 4와 방법 5 비교 요약
| 구분 | /function API | /function API |
| 적합한 사이트 | 네이버, 일반 동적 사이트 | 쿠팡, 강력한 봇 탐지 사이트 |
| 필요 인프라 | Browserless 컨테이너 | 없음 (n8n만 있으면 됨) |
| 설정 난이도 | 중간 (Puppeteer 문법 이해 필요) | 쉬움 (cURL 복사 붙여넣기) |
| 자동화 수준 | 완전 자동화 가능 | 반자동 (쿠키 갱신 필요) |
| 유지보수 | 낮음 | 중간 (주기적 쿠키 갱신) |
| 봇 탐지 우회 | 일부 가능 | 브라우저 세션 기반으로 우회 |
n8n 워크플로우 전체 구성
실제 n8n 워크플로우에서는 Browserless 호출 외에도 데이터 처리와 저장을 위한 추가 노드가 필요합니다. 아래는 권장하는 워크플로우 구성으로, 각 단계에서의 역할과 설정 방법을 함께 설명합니다.
[Schedule Trigger] → [HTTP Request (Browserless)] → [Code (데이터 정제)] → [Google Sheets/Airtable]
↓
(매일 오전 9시) ↓ ↓
리뷰 JSON 수신 필요한 필드만 추출
Code 노드 - 데이터 정제 예시:
// HTTP Request 응답에서 리뷰 데이터 추출
const responseData = $input.first().json;
// 응답이 배열인 경우 (리뷰 목록)
if (Array.isArray(responseData)) {
return responseData.map(review => ({
json: {
rating: review.rating,
content: review.content,
date: review.date,
userName: review.userName,
crawledAt: new Date().toISOString()
}
}));
}
// 응답이 객체인 경우 (API 응답)
if (responseData.reviews) {
return responseData.reviews.map(review => ({
json: {
rating: review.rating,
content: review.content,
date: review.date,
userName: review.userName,
crawledAt: new Date().toISOString()
}
}));
}
return [{ json: responseData }];10. 자주 발생하는 문제와 해결 방법
문제 1 | 403 Forbidden 또는 Bot Detection 오류
쿠팡의 봇 탐지 시스템은 다양한 신호를 분석하여 자동화된 접근을 차단합니다. User-Agent만 변경해서는 충분하지 않으며, 브라우저 지문(fingerprint) 전체가 일관성 있게 구성되어야 합니다. Browserless의 stealth 플러그인을 활성화하면 일반적인 봇 탐지를 우회할 수 있습니다.
# 해결 방법
{
"code": "module.exports = async ({ page }) => {\n // Stealth 모드 강화\n await page.evaluateOnNewDocument(() => {\n Object.defineProperty(navigator, 'webdriver', { get: () => undefined });\n Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5] });\n Object.defineProperty(navigator, 'languages', { get: () => ['ko-KR', 'ko', 'en-US', 'en'] });\n });\n \n // 나머지 크롤링 코드...\n};"
}문제 2 | 세션/쿠키 만료
크롤링 중 세션이 만료되면 인증 오류가 발생할 수 있습니다. 특히 장시간 실행되는 워크플로우에서는 쿠키의 유효 기간을 주의해야 합니다. 매 요청마다 새로운 브라우저 세션을 시작하거나, 쿠키를 주기적으로 갱신하는 로직이 필요합니다.
해결 방법 - 매 요청마다 새 세션 사용:
Browserless의 기본 동작은 매 요청마다 새로운 브라우저 컨텍스트를 생성하므로, 별도의 설정 없이도 세션 문제를 피할 수 있습니다. 다만 이 경우 매번 페이지 로딩이 필요하므로 처리 시간이 늘어납니다.
문제 3 | Timeout 오류
쿠팡 페이지는 많은 리소스를 로드하기 때문에 기본 타임아웃(30초) 내에 완료되지 않을 수 있습니다. 특히 네트워크 상태가 불안정하거나, 서버 응답이 느린 시간대에는 타임아웃 값을 넉넉하게 설정하는 것이 좋습니다.
{
"code": "module.exports = async ({ page }) => {\n page.setDefaultTimeout(120000); // 2분으로 설정\n page.setDefaultNavigationTimeout(120000);\n \n await page.goto('https://www.coupang.com/...', {\n waitUntil: 'domcontentloaded', // networkidle2 대신 사용\n timeout: 120000\n });\n \n // ...\n};"
}
문제 4 | Docker 네트워크 연결 오류
n8n과 Browserless가 다른 Docker 네트워크에 있으면 서로 통신할 수 없습니다. 동일한 네트워크에 연결하거나, 호스트 네트워크 모드를 사용해야 합니다.
# docker-compose.yml
version: '3.8'
services:
n8n:
image: n8nio/n8n:latest
container_name: n8n
networks:
- automation-network
# ... 기타 설정
browserless:
image: browserless/chrome:latest
container_name: browserless
networks:
- automation-network
environment:
- CONNECTION_TIMEOUT=120000
- MAX_CONCURRENT_SESSIONS=10
ports:
- "3000:3000"
networks:
automation-network:
driver: bridge11. 실전 팁 - 안정적인 크롤링을 위한 베스트 프랙티스
요청 속도 조절
짧은 시간에 너무 많은 요청을 보내면 IP가 차단될 수 있습니다. n8n의 Wait 노드를 활용하여 요청 간 적절한 딜레이를 주는 것이 좋습니다. 일반적으로 3-5초 정도의 간격을 두면 대부분의 사이트에서 안전하게 크롤링할 수 있습니다.
에러 핸들링
크롤링은 외부 요인에 의해 실패할 가능성이 높으므로, 적절한 에러 핸들링이 필수입니다. n8n의 Error Trigger 노드와 IF 노드를 조합하여 실패 시 재시도하거나 알림을 보내는 로직을 구성할 수 있습니다.
[HTTP Request] → [IF (성공?)] → Yes → [데이터 처리]
↓
No → [Wait 10초] → [HTTP Request (재시도)]
로깅과 모니터링
크롤링 결과를 로깅하면 문제 발생 시 원인을 파악하기 쉽습니다. 수집한 데이터 건수, 실패 건수, 소요 시간 등을 기록해 두면 크롤링 패턴의 변화나 차단 여부를 빠르게 감지할 수 있습니다.
이 글에서는 n8n에서 Browserless를 활용하여 쿠팡 리뷰를 크롤링하는 방법을 살펴보았습니다. Browserless의 /function API를 활용하면 실제 브라우저 환경에서 JavaScript를 실행하고, 쿠키 기반 인증이 필요한 API에도 접근할 수 있습니다. 핵심은 먼저 상품 페이지에 접속하여 유효한 세션을 확보한 후, 해당 세션 내에서 리뷰 API를 호출하는 것입니다.
웹 크롤링은 대상 사이트의 이용약관과 robots.txt를 준수하는 범위 내에서 수행해야 합니다. 또한 과도한 요청으로 서버에 부담을 주지 않도록 적절한 속도 조절이 필요합니다. 또한, 법적인 제한이 있는 경우는 법/제도 틀안에서의 웹 크롤링을 수행하는 것이 좋습니다. 앞 장에서 말씀드린것과 같이 쿠팡은 동적 페이지에 대한 단순한 예시 일 뿐, 쿠팡 파터너스에서 적합한 API를 제공하기 때문에 실질적인 제품 리뷰가 필요한 경우는 해당 API를 사용하는 것이 가장 안전하고 정확한 데이터를 수집할 수 있습니다. 이 가이드가 n8n과 Browserless를 활용한 자동화 워크플로우 구축에 도움이 되기를 바랍니다.
'AI 활용' 카테고리의 다른 글
| n8n-workflow-builder MCP를 활용한 AI 워크플로우 자동 생성하기 (1) | 2025.12.23 |
|---|---|
| n8n+MCP 통합 기반 AI에이전트 워크플로우 관리하기 (0) | 2025.12.23 |
| n8n에서 동적 웹페이지를 크롤링하는 방법 : curl, Headless 브라우저 설치 (0) | 2025.12.20 |
| n8n 환경에서 챗봇 위젯 웹페이지 구성하기 (0) | 2025.12.20 |
| n8n 원격 네트워크 데이터베이스 연결하기 (0) | 2025.12.20 |



